
1.它们叫作函数。
2.这将导致在最终的编译之前,使用iostream文件的内容替换该编译指令。
3.它使得程序可以使用std名称空间中的定义。
4.
或

5.int cheeses;
6.cheeses = 32;
7.cin >> cheeses;
8.cout << "We have " << cheeses << " varieties of cheese\n";
9.调用函数froop( )时,应提供一个参数,该参数的类型为double,而该函数将返回一个int值。例如,可以像下面这样使用它:
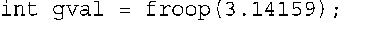
函数rattle( )接受一个int参数且没有返回值。例如,可以这样使用它:

函数prune( )不接受任何参数且返回一个int值。例如,可以这样使用它:
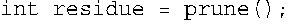
10.当函数的返回类型为void时,不用在函数中使用return。然而,如果不提供返回值,则可以使用它:

1.有多种整型类型,可以根据特定需求选择最适合的类型。例如,可以使用short来存储空格,使用long来确保存储容量,也可以寻找可提高特定计算的速度的类型。
2.

注意:不要指望int变量能够存储3000000000;另外,如果系统支持通用的列表初始化,可使用它:
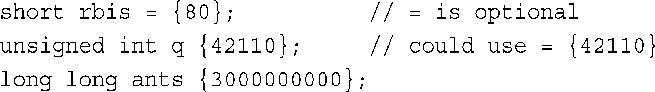
3.C++没有提供自动防止超出整型限制的功能,可以使用头文件climits来确定限制情况。
4.常量33L的类型为long,常量33的类型为int。
5.这两条语句并不真正等价,虽然对于某些系统来说,它们是等效的。最重要的是,只有在使用ASCII码的系统上,第一条语句才将得分设置为字母A,而第二条语句还可用于使用其他编码的系统。其次,65是一个int常量,而‘A’是一个char常量。
6.下面是4种方式:

7.这个问题的答案取决于这两个类型的长度。如果long为4个字节,则没有损失。因为最大的long值将是20亿,即有10位数。由于double提供了至少13位有效数字,因而不需要进行任何舍入。long long类型可提供19位有效数字,超过了double保证的13位有效数字。
8.
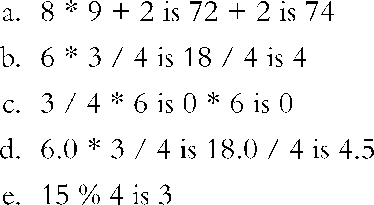
9.下面的代码都可用于完成第一项任务:
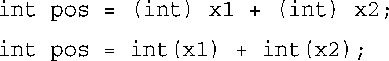
要将它们作为double类型相加,再进行转换,可采取下述方式之一:
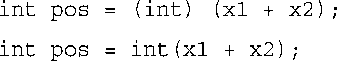
10.

1.

2.

3.int oddly[5] = {1,3,5,7,9};
4.int even = oddly[0] + oddly[4];
5.cout << ideas[1] << "\n"; // or << endl;
6.char lunch[13] = "cheeseburger";// number of characters + 1
或者
char lunch[] = "cheeseburger"; // let the compiler count elements
7.
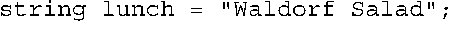
如果没有using编译指令,则为:
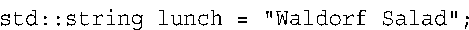
8.

9.

10. 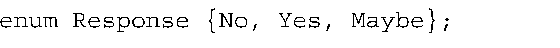
11.
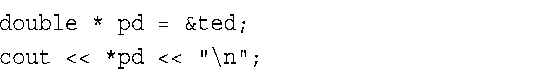
12.

13.这里假设已经包含了头文件iostream和vector,并有一条using编译指令:

14.是的,它是有效的。表达式“home of the jolly bytes”是一个字符串常量,因此,它将判定为字符串开始的地址。cout对象将char地址解释为打印字符串,但类型转换(int *)将地址转换为int指针,然后作为地址被打印。总之,该语句打印字符串的地址,只要int类型足够宽,能够存储该地址。
15.

16.使用cin >>address将使得程序跳过空白,直到找到非空白字符为止。然后它将读取字符,直到再次遇到空白为止。因此,它将跳过数字输入后的换行符,从而避免这种问题。另一方面,它只读取一个单词,而不是整行。
17.

1.输入条件循环在进入输入循环体之前将评估测试表达式。如果条件最初为false,则循环不会执行其循环体。退出条件循环在处理循环体之后评估测试表达式。因此,即使测试表达式最初为false,循环也将执行一次。for和while循环都是输入条件循环,而do while循环是退出条件循环。
2.它将打印下面的内容:
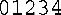
注意,cout<< endl;不是循环体的组成部分,因为没有大括号。
3.它将打印下面的内容:
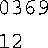
4.它将打印下面的内容:

5.它将打印下面的内容:
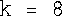
6.使用*= 运算符最简单:
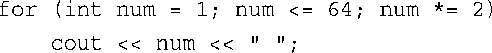
7.将语句放在一对大括号中将形成一个复合语句或代码块。
8.当然,第一条语句是有效的。表达式1,024由两个表达式组成—1和024,用逗号运算符连接。值为右侧表达式的值。这是024,八进制为20,因此该声明将值20赋给X。第二条语句也是有效的。然而,运算符优先级将导致它被判定成这样:
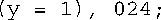
也就是说,左侧表达式将y设置成1,整个表达式的值(没有使用)为024或20(八进制)。
9.cin>> ch将跳过空格、换行符和制表符,其他两种格式将读取这些字符。
1.这两个版本将给出相同的答案,但if else版本的效率更高。例如,考虑当ch为空格时的情况。版本1对空格加1,然后看它是否为换行符。这将浪费时间,因为程序已经知道ch为空格,因此它不是换行符。在这种情况下,版本2将不会查看字符是否为换行符。
2.++ch和ch + 1得到的数值相同。但++ch的类型为char,将作为字符打印,而ch + 1是int类型(因为将char和int相加),将作为数字打印。
3.由于程序使用ch = '$',而不是ch = ='$',因此输入和输出将如下:
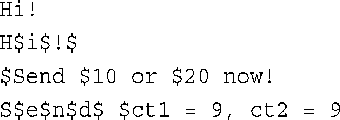
在第二次打印前,每个字符都被转换为$字符。另外,表达式ch=$的值为$字符的编码,因此它是非0值,因而为true;所以每次ct2将被加1。
4.
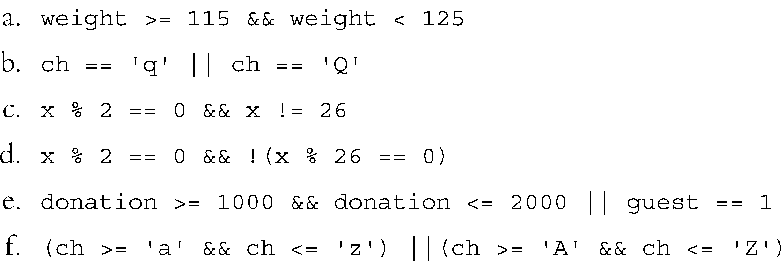
5.不一定。例如,如果x为10,则!x为0,!!x为1。然而,如果x为bool变量,则!!x为x。
6.
或
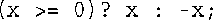
7.

8.如果使用整数标签,且用户输入了非整数(如q),则程序将因为整数输入不能处理字符而挂起。但是,如果使用字符标签,而用户输入了整数(如5),则字符输入将5作为字符处理。然后,switch语句的default部分将提示输入另一个字符。
9.下面是一个版本:

1.这3个步骤是定义函数、提供原型、调用函数。
2.

3.

4.

5.


6.将const限定符用于指针,以防止指向的原始数据被修改。程序传递基本类型(如int或double)时,它将按值传递,以便函数使用副本。这样,原始数据将得到保护。
7.字符串可以存储在char数组中,可以用带双引号的字符串来表示,也可以用指向字符串第一个字符的指针来表示。
8.

9.由于C++将“pizza”解释为其第一个元素的地址,因此使用*运算符将得到第一个元素的值,即字符p。由于C++将“taco”解释为第一个元素的地址,因此它将“taco”[2]解释为第二个元素的值,即字符c。换句话来说,字符串常量的行为与数组名相同。
10.要按值传递它,只要传递结构名glitz即可。要传递它的地址,请使用地址运算符&glitz。按值传递将自动保护原始数据,但这是以时间和内存为代价的。按地址传递可节省时间和内存,但不能保护原始数据,除非对函数参数使用了const限定符。另外,按值传递意味着可以使用常规的结构成员表示法,但传递指针则必须使用间接成员运算符。
11.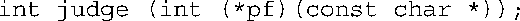
12.a.注意,如果ap是一个applicant结构,则ap.credit_ratings就是一个数组名,而ap.credit_ratings[i]是一个数组元素:

b.注意,如果pa是一个指向applicant结构的指针,则pa->credit_ratings就是一个数组名,而pa->credit_ratings[i]是一个数组元素:

13.

1.只有一行代码的小型、非递归函数适合作为内联函数。
2.a.void song(const char * name,int times = 1);
b.没有。只有原型包含默认值的信息。
c.是的,如果保留times的默认值:
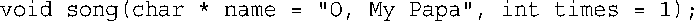
3.可以使用字符串"\""或字符'"'来打印引号,下面的函数演示了这两种方法。


4.a.该函数不应修改结构成员,所以使用const限定符。

b.

5.首先,将原型修改成下面这样:

注意,show( )应使用const,以禁止修改对象。
接下来,在main( )中,将fill( )调用改为下面这样:
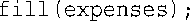
函数show( )的调用不需要修改。
接下来,新的fill( )应类似于下面这样:

注意到(*pa)[i]变成了更简单的pa[i]。
最后,修改show( )的函数头:
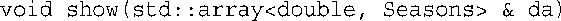
6.a.通过为第二个参数提供默认值:

也可以通过函数重载:
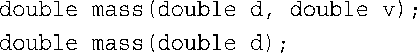
b.不能为重复的值使用默认值,因为必须从右到左提供默认值。可以使用重载:
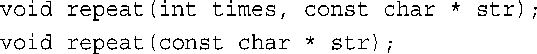
c.可以使用函数重载:
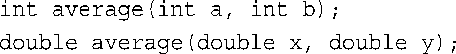
d.不能这样做,因为两个版本的特征标将相同。
7.

8.

9.v1的类型为float,v2的类型为float &,v3的类型为float &,v4的类型为int,v5的类型为double。字面值2.0的类型为double,因此表达式2.0 * m的类型为double。
1.a.homer将自动成为自动变量。
b.应该在一个文件中将secret定义为外部变量,并在第二个文件中使用extern来声明它。
c.可以在外部定义前加上关键字static,将topsecret定义为一个有内部链接的静态变量。也可在一个未命名的名称空间中进行定义。
d.应在函数中的声明前加上关键字static,将beencalled定义为一个本地静态变量。
2.using声明使得名称空间中的单个名称可用,其作用域与using所在的声明区域相同。using编译指令使名称空间中的所有名称可用。使用using编译指令时,就像在一个包含using声明和名称空间本身的最小声明区域中声明了这些名称一样。
3.

4.下面是修改后的代码:


5.可以在每个文件中包含单独的静态函数定义。或者每个文件都在未命名的名称空间中定义一个合适的average( )函数。
6.

7.

1.类是用户定义的类型的定义。类声明指定了数据将如何存储,同时指定了用来访问和操纵这些数据的方法(类成员函数)。
2.类表示人们可以类方法的公有接口对类对象执行的操作,这是抽象。类的数据成员可以是私有的(默认值),这意味着只能通过成员函数来访问这些数据,这是数据隐藏。实现的具体细节(如数据表示和方法的代码)都是隐藏的,这是封装。
3.类定义了一种类型,包括如何使用它。对象是一个变量或其他数据对象(如由new生成的),并根据类定义被创建和使用。类和对象之间的关系同标准类型与其变量之间的关系相同。
4.如果创建给定类的多个对象,则每个对象都有其自己的数据内存空间;但所有的对象都使用同一组成员函数(通常,方法是公有的,而数据是私有的,但这只是策略方面的问题,而不是对类的要求)。
5.这个示例使用char数组来存储字符数据,但可以使用string类对象。

6.在创建类对象或显式调用构造函数时,类的构造函数都将被调用。当对象过期时,类的析构函数将被调用。
7.有两种可能的解决方案(要使用strncpy( ),必须包含头文件cstring或string.h;要使用string类,必须包含头文件string):

或者:


请记住,默认参数位于原型中,而不是函数定义中。
8.默认构造函数是没有参数或所有参数都有默认值的构造函数。拥有默认构造函数后,可以声明对象,而不初始化它,即使已经定义了初始化构造函数。它还使得能够声明数组。
9.

10.this指针是类方法可以使用的指针,它指向用于调用方法的对象。因此,this是对象的地址,*this是对象本身。
1.下面是类定义文件的原型和方法文件的函数定义:

2.成员函数是类定义的一部分,通过特定的对象来调用。成员函数可以隐式访问调用对象的成员,而无需使用成员运算符。友元函数不是类的组成部分,因此被称为直接函数调用。友元函数不能隐式访问类成员,而必须将成员运算符用于作为参数传递的对象。请比较复习题1和复习题4的答案。
3.要访问私有成员,它必须是友元,但要访问公有成员,可以不是友元。
4.下面是类定义文件的原型和方法文件的函数定义:

5.下面的5个运算符不能重载:
6.这些运算符必须使用成员函数来定义。
7.下面是一个可能的原型和定义:
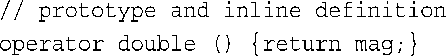
但请注意,使用magval( )方法比定义该转换函数更符合逻辑。
1.a.语法是正确的,但该构造函数没有将str指针初始化。该构造函数应将指针设置成NULL或使用new [ ]来初始化它。
b.该构造函数没有创建新的字符串,而只是复制了原有字符串的地址。它应当使用new [ ]和strcpy( )。
c.它复制了字符串,但没有给它分配存储空间,应使用new char[len + 1]来分配适当数量的内存。
2.首先,当这种类型的对象过期时,对象的成员指针指向的数据仍将保留在内存中,这将占用空间,同时不可访问,因为指针已经丢失。可以让类析构函数删除构造函数中new分配的内存,来解决这种问题。其次,析构函数释放这种内存后,如果程序将这样的对象初始化为另一个对象,则析构函数将试图释放这些内存两次。这是因为将一个对象初始化为另一个对象的默认初始化,将复制指针值,但不复制指向的数据,这将使两个指针指向相同的数据。解决方法是,定义一个复制构造函数,使初始化复制指向的数据。第三,将一个对象赋给另一个对象也将导致两个指针指向相同的数据。解决方法是重载赋值运算符,使之复制数据,而不是指针。
3.C++自动提供下面的成员函数:
默认构造函数不完成任何工作,但使得能够声明数组和未初始化的对象。默认复制构造函数和默认赋值运算符使用成员赋值。默认析构函数也不完成任何工作。隐式地址运算符返回调用对象的地址(即this指针的值)。
4.应将personality成员声明为字符数组或car指针,或者将其声明为String对象或string对象。该声明没有将方法设置为公有的,因此会有几个小错误。下面是一种可能的解决方法,修改的地方以粗体显示:

下面是另一种解决方案:


5.a.

注意,对于语句5和6,有些编译器还将调用默认的赋值运算符。
b.类应定义一个复制数据(而不是地址)的赋值运算符。
1.基类的公有成员成为派生类的公有成员。基类的保护成员成为派生类的保护成员。基类的私有成员被继承,但不能直接访问。复习题2的答案提供了这些通用规定的特例。
2.不能继承构造函数、析构函数、赋值运算符和友元。
3.如果返回的类型为void,仍可以使用单个赋值,但不能使用连锁赋值:

如果方法返回一个对象,而不是引用,则该方法的执行速度将有所减慢,这是因为返回语句需要复制对象。
4.按派生的顺序调用构造函数,最早的构造函数最先调用。调用析构函数的顺序正好相反。
5.是的,每个类都必须有自己的构造函数。如果派生类没有添加新成员,则构造函数可以为空,但必须存在。
6.只调用派生类方法。它取代基类定义。仅当派生类没有重新定义方法或使用作用域解析运算符时,才会调用基类方法。然而,应把将所有要重新定义的函数声明为虚函数。
7.如果派生类构造函数使用new或new[ ]运算符来初始化类的指针成员,则应定义一个赋值运算符。更普遍地说,如果对于派生类成员来说,默认赋值不正确,则应定义赋值运算符。
8.当然,可以将派生类对象的地址赋给基类指针;但只有通过显式类型转换,才可以将基类对象的地址赋给派生类指针(向下转换),而使用这样的指针不一定安全。
9.是的,可以将派生类对象赋给基类对象。对于派生类中新增的数据成员都不会传递给基类对象。然而,程序将使用基类的赋值运算符。仅当派生类定义了转换运算符(即包含将基类引用作为唯一参数的构造函数)或使用基类为参数的赋值运算符时,相反方向的赋值才是可能的。
10.它可以这样做,因为C++允许基类引用指向从该基类派生而来的任何类型。
11.按值传递对象将调用复制构造函数。由于形参是基类对象,因此将调用基类的复制构造函数。复制构造函数以基类引用为参数,该引用可以指向作为参数传递的派生对象。最终结果是,将生成一个新的基类对象,其成员对应于派生对象的基类部分。
12.按引用(而不是按值)传递对象,这样可以确保函数从虚函数受益。另外,按引用(而不是按值)传递对象可以节省内存和时间,尤其对于大型对象。按值传递对象的主要优点在于可以保护原始数据,但可以通过将引用作为const类型传递,来达到同样的目的。
13.如果head( )是一个常规方法,则ph->head( )将调用Corporation::head( );如果head( )是一个虚函数,则ph->head( )将调用PublicCorporation::head( )。
14.首先,这种情况不符合is-a模型,因此公有继承不适用。其次,House中的area( )定义隐藏了area( )的Kitchen版本,因为这两个方法的特征标不同。
1.
|
Class Bear |
class PolarBear |
公有,北极熊是一种熊 |
|---|---|---|
|
class Kitchen |
class Home |
私有,家里有厨房 |
|
class Person |
class Programmer |
公有,程序员是一种人 |
|
class Person |
class HorseAndJockey |
私有,马和驯马师的组合中包含一个人 |
|
class Person class Automobile |
class Driver |
人是公有的,因为司机是一个人;汽车是私有的,因为司机有一辆汽车 |
2.

3.

4.

5.

程序清单14.18生成4个模板:ArrayTP<int, 10>、ArrayTP<double, 10>、ArrayTP<int, 5>和Array<ArrayTP <int, 5>, 10>。
6.如果两条继承路线有相同的祖先,则类中将包含祖先成员的两个拷贝。将祖先类作为虚基类可以解决这种问题。
1.a.友元声明如下:
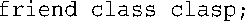
b.这需要一个前向声明,以便编译器能够解释void snip(muff&):

c.首先,cuff类声明应在muff类之前,以便编译器可以理解cuff::snip( )。其次,编译器需要muff的一个前向声明,以便可以理解snip(muff &)。

2.不。为使类A拥有一个本身为类B的成员函数的友元,B的声明必须位于A的声明之前。一个前向声明是不够的,因为这种声明可以告诉A:B是一个类;但它不能指出类成员的名称。同样,如果B拥有一个本身是A的成员函数的友元,则A的这个声明必须位于B的声明之前。这两个要求是互斥的。
3.访问类的唯一方法是通过其有接口,这意味着对于Sauce对象,只能调用构造函数来创建一个。其他成员(soy和sugar)在默认情况下是私有的。
4.假设函数f1( )调用函数f2( )。f2( )中的返回语句导致程序执行在函数f1( )中调用函数f2( )后面的一条语句。throw语句导致程序沿函数调用的当前序列回溯,直到找到直接或间接包含对f2( )的调用的try语句块为止。它可能在f1( )中、调用f1( )的函数中或其他函数中。找到这样的try语句块后,将执行下一个匹配的catch语句块,而不是函数调用后的语句。
5.应按从子孙到祖先的顺序排列catch语句块。
6.对于示例#1,如果pg指向一个Superb对象或从Superb派生而来的任何类的对象,则if条件为true。具体地说,如果pg指向Magnificent对象,则if条件也为true。对于示例#2,仅当指向Superb对象时,if条件才为true,如果指向的是从Superb派生出来的对象,则if条件不为true。
7.Dynamic_cast运算符只允许沿类层次结构向上转换,而static_cast运算符允许向上转换和向下转换。static_cast运算符还允许枚举类型和整型之间以及数值类型之间的转换。
1.
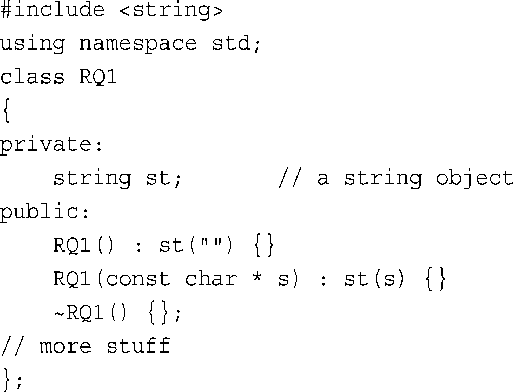
不再需要显式复制构造函数、析构程序和赋值运算符,因为string对象提供了自己的内存管理功能。
2.可以将一个string对象赋给另一个。string对象提供了自己的内存管理功能,所以一般不需要担心字符串超出存储容量。
3.

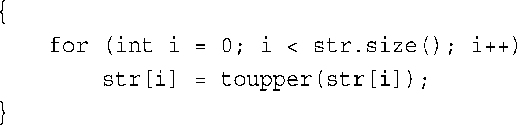
4.

5.栈的LIFO特征意味着可能必须在到达所需要的球棍(club)之前删除很多球棍。
6.集合将只存储每个值的一个拷贝,因此,5个5分将被存储为1个5分。
7.使用迭代器使得能够使用接口类似于指针的对象遍历不以数组方式组织的数据,如双向链表中的数据。
8.STL方法使得可以将STL函数用于指向常规数组的常规指针以及指向STL容器类的迭代器,因此提高了通用性。
9.可以将一个vector对象赋给另一个。vector管理自己的内存,因此可以将元素插入到矢量中,并让它自动调整长度。使用at( )方法,可以自动检查边界。
10.这两个vector函数和random_shuffle( )函数要求随机访问迭代器,而list对象只有双向迭代器。可以使用list模板类的sort( )成员函数(参见附录G),而不是通用函数来排序,但没有与random_shuffle( )等效的成员函数。然而,可以将链表复制到矢量中,然后打乱矢量,并将结果重新复制到链表中。
1.iostream文件定义了用于管理输入和输出的类、常量和操纵符,这些对象管理用于处理I/O的流和缓冲区。该文件还创建了一些标准对象(cin、cout、cerr和clog以及对应的宽字符对象),用于处理与每个程序相连的标准输入和输出流。
2.键盘输入生成一系列字符。输入121将生成3个字符,每个字符都由一个1字节的二进制码表示。要将这个值存储为int类型,则必须将这3个字符转换为121值的二进制表示。
3.在默认情况下,标准输出和标准错误都将输出发送给标准输出设备(通常为显示器)。然而,如果要求操作系统将输出重定向到文件,则标准输出将与文件(而不是显示器)相连,但标准错误仍与显示器相连。
4.ostream类为每种C++基本类型定义了一个operator <<( )函数的版本。编译器将下面的表达式:
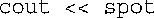
解释为:
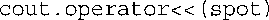
这样,它便能够将该方法调用与具有相同参数类型的函数原型匹配。
5.可以将返回ostream &类型的输出方法拼接。这样,通过一个对象调用方法时,将返回该对象。然后,返回对象将可以调用序列中的下一个方法。
6.

7.
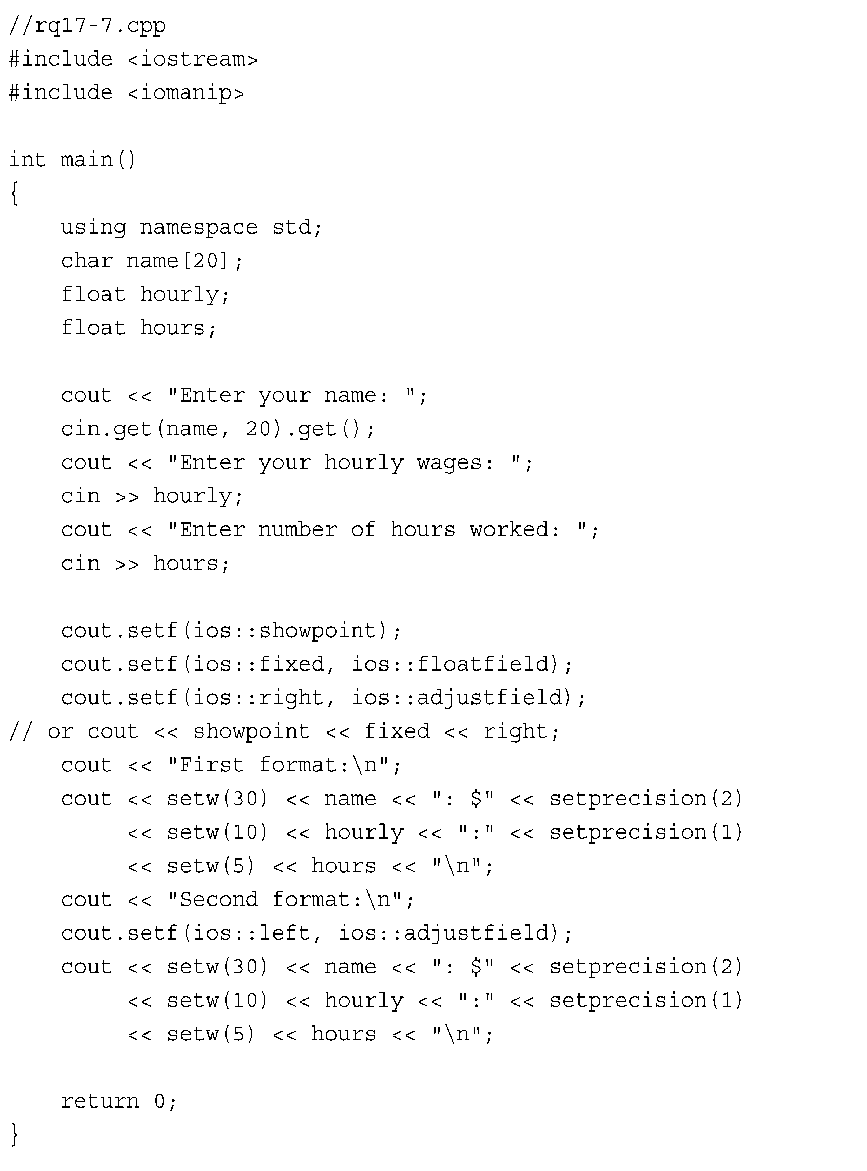
8.下面是输出:
该程序的前半部分忽略空格和换行符,而后半部分没有。注意,程序的后半部分从第一个q后面的换行符开始读取,将换行符计算在内。
9.如果输入行超过80个字符,ignore( )将不能正常工作。在这种情况下,它将跳过前80个字符。
1.

2.r1(w)合法,形参rx指向w。
r1(w+1)合法,形参rx指向一个临时变量,这个变量被初始化为w+1。
r1(up(w))合法,形参rx指向一个临时变量,这个变量被初始化为up(w)的返回值。
一般而言,将左值传递给const左值引用参数时,参数将被初始化为左值。将右值传递给函数时,const左值引用参数将指向右值的临时拷贝。
r2(w)合法,形参rx指向w。
r2(w+1)非法,因为w+1是一个右值。
r2(up(w))非法,因为up(w)的返回值是一个右值。
一般而言,将左值传递给非const左值引用参数时,参数将被初始化为左值;但非const左值形参不能接受右值实参。
r3(w)非法,因为右值引用不能指向左值(如w)。
r3(w+1)合法,rx指向表达式w+1的临时拷贝。
r3(up(w))合法,rx指向up(w)的临时返回值。
3.
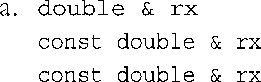
非const左值引用与左值实参w匹配。其他两个实参为右值,const左值引用可指向它们的拷贝。
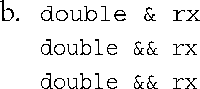
左值引用与左值实参w匹配,而右值引用与两个右值实参匹配。

const左值引用与左值实参w匹配,而右值引用与两个右值实参匹配。
总之,非const左值形参与左值实参匹配,非const右值形参与右值实参匹配;const左值形参可与左值或右值形参匹配,但编译器优先选择前两种方式(如果可供选择的话)。
4.它们是默认构造函数、复制构造函数、移动构造函数、析构函数、复制赋值运算符和移动赋值运算符。这些函数之所以特殊,是因为编译器将根据情况自动提供它们的默认版本。
5.在转让数据所有权(而不是复制数据)可行时,可使用移动构造函数,但对于标准数组,没有转让其所有权的机制。如果Fizzle使用指针和动态内存分配,则可将数据的地址赋给新指针,以转让其所有权。
6.

7.
