5
Procedures

In a procedural programming language, the basic unit of code is the procedure. A procedure is a set of instructions that compute a value or take an action (such as printing or reading a character value). This chapter discusses how MASM implements procedures, parameters, and local variables. By the end of this chapter, you should be well versed in writing your own procedures and functions, and fully understand parameter passing and the Microsoft ABI calling convention.
5.1 Implementing Procedures
Most procedural programming languages implement procedures by using the call/return mechanism. The code calls a procedure, the procedure does its thing, and then the procedure returns to the caller. The call and return instructions provide the x86-64’s procedure invocation mechanism. The calling code calls a procedure with the call instruction, and the procedure returns to the caller with the ret instruction. For example, the following x86-64 instruction calls the C Standard Library printf() function:
call printfAlas, the C Standard Library does not supply all the routines you will ever need. Most of the time you’ll have to write your own procedures. To do this, you will use MASM’s procedure-declaration facilities. A basic MASM procedure declaration takes the following form:
proc_name proc options
Procedure statements
proc_name endpProcedure declarations appear in the .code section of your program. In the preceding syntax example, proc_name represents the name of the procedure you wish to define. This can be any valid (and unique) MASM identifier.
Here is a concrete example of a MASM procedure declaration. This procedure stores 0s into the 256 double words that RCX points at upon entry into the procedure:
zeroBytes proc
mov eax, 0
mov edx, 256
repeatlp: mov [rcx+rdx*4-4], eax
dec rdx
jnz repeatlp
ret
zeroBytes endpAs you’ve probably noticed, this simple procedure doesn’t bother with the “magic” instructions that add and subtract a value to and from the RSP register. Those instructions are a requirement of the Microsoft ABI when the procedure will be calling other C/C++ code (or other code written in a Microsoft ABI–compliant language). Because this little function doesn’t call any other procedures, it doesn’t bother executing such code. Also note that this code uses the loop index to count down from 256 to 0, filling in the 256 dword array backward (from end to beginning) rather than filling it in from beginning to end. This is a common technique in assembly language.
You can use the x86-64 call instruction to call this procedure. When, during program execution, the code falls into the ret instruction, the procedure returns to whoever called it and begins executing the first instruction beyond the call instruction. The program in Listing 5-1 provides an example of a call to the zeroBytes routine.
; Listing 5-1
; Simple procedure call example.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 5-1", 0
.data
dwArray dword 256 dup (1)
.code
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; Here is the user-written procedure
; that zeroes out a buffer.
zeroBytes proc
mov eax, 0
mov edx, 256
repeatlp: mov [rcx+rdx*4-4], eax
dec rdx
jnz repeatlp
ret
zeroBytes endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
; "Magic" instruction offered without
; explanation at this point:
sub rsp, 48
lea rcx, dwArray
call zeroBytes
add rsp, 48 ; Restore RSP
ret ; Returns to caller
asmMain endp
endListing 5-1: Example of a simple procedure
5.1.1 The call and ret Instructions
The x86-64 call instruction does two things. First, it pushes the (64-bit) address of the instruction immediately following the call onto the stack; then it transfers control to the address of the specified procedure. The value that call pushes onto the stack is known as the return address.
When the procedure wants to return to the caller and continue execution with the first statement following the call instruction, most procedures return to their caller by executing a ret (return) instruction. The ret instruction pops a (64-bit) return address off the stack and transfers control indirectly to that address.
The following is an example of the minimal procedure:
minimal proc
ret
minimal endpIf you call this procedure with the call instruction, minimal will simply pop the return address off the stack and return to the caller. If you fail to put the ret instruction in the procedure, the program will not return to the caller upon encountering the endp statement. Instead, the program will fall through to whatever code happens to follow the procedure in memory.
The example program in Listing 5-2 demonstrates this problem. The main program calls noRet, which falls straight through to followingProc (printing the message followingProc was called).
; Listing 5-2
; A procedure without a ret instruction.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 5-2", 0
fpMsg byte "followingProc was called", nl, 0
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; noRet - Demonstrates what happens when a procedure
; does not have a return instruction.
noRet proc
noRet endp
followingProc proc
sub rsp, 28h
lea rcx, fpMsg
call printf
add rsp, 28h
ret
followingProc endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbx
sub rsp, 40 ; "Magic" instruction
call noRet
add rsp, 40 ; "Magic" instruction
pop rbx
ret ; Returns to caller
asmMain endp
endListing 5-2: Effect of a missing ret instruction in a procedure
Although this behavior might be desirable in certain rare circumstances, it usually represents a defect in most programs. Therefore, always remember to explicitly return from the procedure by using the ret instruction.
5.1.2 Labels in a Procedure
Procedures may contain statement labels, just like the main procedure in your assembly language program (after all, the main procedure, asmMain in most of the examples in this book, is just another procedure declaration as far as MASM is concerned). Note, however, that statement labels defined within a procedure are local to that procedure; such symbols are not visible outside the procedure.
In most situations, having scoped symbols in a procedure is nice (see “Local (Automatic) Variables” on page 234 for a discussion of scope). You don’t have to worry about namespace pollution (conflicting symbol names) among the different procedures in your source file. Sometimes, however, MASM’s name scoping can create problems. You might actually want to refer to a statement label outside a procedure.
One way to do this on a label-by-label basis is to use a global statement label declaration. Global statement labels are similar to normal statement labels in a procedure except you follow the symbol with two colons instead of a single colon, like so:
globalSymbol:: mov eax, 0Global statement labels are visible outside the procedure. You can use an unconditional or conditional jump instruction to transfer control to a global symbol from outside the procedure; you can even use a call instruction to call that global symbol (in which case, it becomes a second entry point to the procedure). Generally, having multiple entry points to a procedure is considered bad programming style, and the use of multiple entry points often leads to programming errors. As such, you should rarely use global symbols in assembly language procedures.
If, for some reason, you don’t want MASM to treat all the statement labels in a procedure as local to that procedure, you can turn scoping on and off with the following statements:
option scoped
option noscopedThe option noscoped directive disables scoping in procedures (for all procedures following the directive). The option scoped directive turns scoping back on. Therefore, you can turn scoping off for a single procedure (or set of procedures) and turn it back on immediately afterward.
5.2 Saving the State of the Machine
Take a look at Listing 5-3. This program attempts to print 20 lines of 40 spaces and an asterisk. Unfortunately, a subtle bug creates an infinite loop. The main program uses the jnz printLp instruction to create a loop that calls PrintSpaces 20 times. This function uses EBX to count off the 40 spaces it prints, and then returns with ECX containing 0. The main program then prints an asterisk and a newline, decrements ECX, and then repeats because ECX isn’t 0 (it will always contain 0FFFF_FFFFh at this point).
The problem here is that the print40Spaces subroutine doesn’t preserve the EBX register. Preserving a register means you save it upon entry into the subroutine and restore it before leaving. Had the print40Spaces subroutine preserved the contents of the EBX register, Listing 5-3 would have functioned properly.
; Listing 5-3
; Preserving registers (failure) example.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 5-3", 0
space byte " ", 0
asterisk byte '*, %d', nl, 0
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; print40Spaces - Prints out a sequence of 40 spaces
; to the console display.
print40Spaces proc
sub rsp, 48 ; "Magic" instruction
mov ebx, 40
printLoop: lea rcx, space
call printf
dec ebx
jnz printLoop ; Until EBX == 0
add rsp, 48 ; "Magic" instruction
ret
print40Spaces endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbx
; "Magic" instruction offered without
; explanation at this point:
sub rsp, 40 ; "Magic" instruction
mov rbx, 20
astLp: call print40Spaces
lea rcx, asterisk
mov rdx, rbx
call printf
dec rbx
jnz astLp
add rsp, 40 ; "Magic" instruction
pop rbx
ret ; Returns to caller
asmMain endp
endListing 5-3: Program with an unintended infinite loop
You can use the x86-64’s push and pop instructions to preserve register values while you need to use them for something else. Consider the following code for PrintSpaces:
print40Spaces proc
push rbx
sub rsp, 40 ; "Magic" instruction
mov ebx, 40
printLoop: lea rcx, space
call printf
dec ebx
jnz printLoop ; Until EBX == 0
add rsp, 40 ; "Magic" instruction
pop rbx
ret
print40Spaces endpprint40Spaces saves and restores RBX by using push and pop instructions. Either the caller (the code containing the call instruction) or the callee (the subroutine) can take responsibility for preserving the registers. In the preceding example, the callee preserves the registers.
Listing 5-4 shows what this code might look like if the caller preserves the registers (for reasons that will become clear in “Saving the State of the Machine, Part II” on page 280, the main program saves the value of RBX in a static memory location rather than using the stack).
; Listing 5-4
; Preserving registers (caller) example.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 5-4", 0
space byte " ", 0
asterisk byte '*, %d', nl, 0
.data
saveRBX qword ?
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; print40Spaces - Prints out a sequence of 40 spaces
; to the console display.
print40Spaces proc
sub rsp, 48 ; "Magic" instruction
mov ebx, 40
printLoop: lea rcx, space
call printf
dec ebx
jnz printLoop ; Until EBX == 0
add rsp, 48 ; "Magic" instruction
ret
print40Spaces endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbx
; "Magic" instruction offered without
; explanation at this point:
sub rsp, 40
mov rbx, 20
astLp: mov saveRBX, rbx
call print40Spaces
lea rcx, asterisk
mov rdx, saveRBX
call printf
mov rbx, saveRBX
dec rbx
jnz astLp
add rsp, 40
pop rbx
ret ; Returns to caller
asmMain endp
endListing 5-4: Demonstration of caller register preservation
Callee preservation has two advantages: space and maintainability. If the callee (the procedure) preserves all affected registers, only one copy of the push and pop instructions exists—those the procedure contains. If the caller saves the values in the registers, the program needs a set of preservation instructions around every call. This makes your programs not only longer but also harder to maintain. Remembering which registers to save and restore on each procedure call is not easily done.
On the other hand, a subroutine may unnecessarily preserve some registers if it preserves all the registers it modifies. In the preceding examples, the print40Spaces procedure didn’t save RBX. Although print40Spaces changes RBX, this won’t affect the program’s operation. If the caller is preserving the registers, it doesn’t have to save registers it doesn’t care about.
One big problem with having the caller preserve registers is that your program may change over time. You may modify the calling code or the procedure to use additional registers. Such changes, of course, may change the set of registers that you must preserve. Worse still, if the modification is in the subroutine itself, you will need to locate every call to the routine and verify that the subroutine does not change any registers the calling code uses.
Assembly language programmers use a common convention with respect to register preservation: unless there is a good reason (performance) for doing otherwise, most programmers will preserve all registers that a procedure modifies (and that doesn’t explicitly return a value in a modified register). This reduces the likelihood of defects occurring in a program because a procedure modifies a register the caller expects to be preserved. Of course, you could follow the rules concerning the Microsoft ABI with respect to volatile and nonvolatile registers; however, such calling conventions impose their own inefficiencies on programmers (and other programs).
Preserving registers isn’t all there is to preserving the environment. You can also push and pop variables and other values that a subroutine might change. Because the x86-64 allows you to push and pop memory locations, you can easily preserve these values as well.
5.3 Procedures and the Stack
Because procedures use the stack to hold the return address, you must exercise caution when pushing and popping data within a procedure. Consider the following simple (and defective) procedure:
MessedUp proc
push rax
ret
MessedUp endpAt the point the program encounters the ret instruction, the x86-64 stack takes the form shown in Figure 5-1.
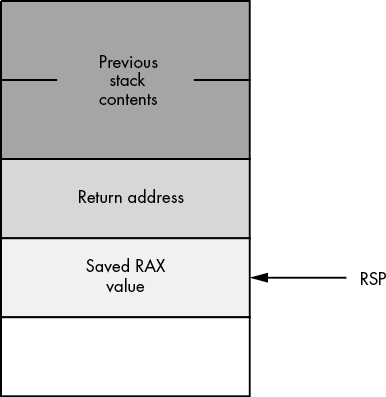
Figure 5-1: Stack contents before ret in the MessedUp procedure
The ret instruction isn’t aware that the value on the top of the stack is not a valid address. It simply pops whatever value is on top and jumps to that location. In this example, the top of the stack contains the saved RAX value. Because it is very unlikely that RAX’s value pushed on the stack was the proper return address, this program will probably crash or exhibit another undefined behavior. Therefore, when pushing data onto the stack within a procedure, you must take care to properly pop that data prior to returning from the procedure.
Popping extra data off the stack prior to executing the ret statement can also create havoc in your programs. Consider the following defective procedure:
MessedUp2 proc
pop rax
ret
MessedUp2 endpUpon reaching the ret instruction in this procedure, the x86-64 stack looks something like Figure 5-2.
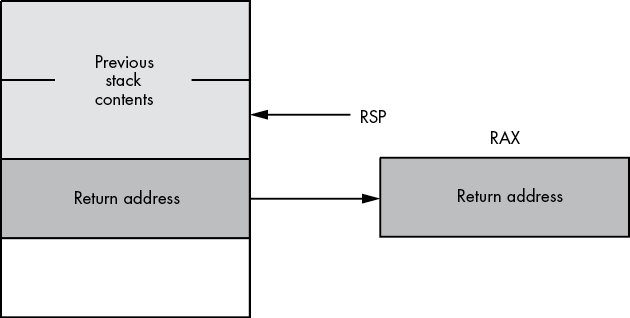
Figure 5-2: Stack contents before ret in MessedUp2
Once again, the ret instruction blindly pops whatever data happens to be on the top of the stack and attempts to return to that address. Unlike the previous example, in which the top of the stack was unlikely to contain a valid return address (because it contained the value in RAX), there is a small possibility that the top of the stack in this example does contain a return address. However, this will not be the proper return address for the messedUp2 procedure; instead, it will be the return address for the procedure that called messedUp2. To understand the effect of this code, consider the program in Listing 5-5.
; Listing 5-5
; Popping a return address by mistake.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 5-5", 0
calling byte "Calling proc2", nl, 0
call1 byte "Called proc1", nl, 0
rtn1 byte "Returned from proc 1", nl, 0
rtn2 byte "Returned from proc 2", nl, 0
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; proc1 - Gets called by proc2, but returns
; back to the main program.
proc1 proc
pop rcx ; Pops return address off stack
ret
proc1 endp
proc2 proc
call proc1 ; Will never return
; This code never executes because the call to proc1
; pops the return address off the stack and returns
; directly to asmMain.
sub rsp, 40
lea rcx, rtn1
call printf
add rsp, 40
ret
proc2 endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
sub rsp, 40
lea rcx, calling
call printf
call proc2
lea rcx, rtn2
call printf
add rsp, 40
ret ; Returns to caller
asmMain endp
endListing 5-5: Effect of popping too much data off the stack
Because a valid return address is sitting on the top of the stack when proc1 is entered, you might think that this program will actually work (properly). However, when returning from the proc1 procedure, this code returns directly to the asmMain program rather than to the proper return address in the proc2 procedure. Therefore, all code in the proc2 procedure that follows the call to proc1 does not execute.
When reading the source code, you may find it very difficult to figure out why those statements are not executing, because they immediately follow the call to the proc1 procedure. It isn’t clear, unless you look very closely, that the program is popping an extra return address off the stack and therefore doesn’t return to proc2 but rather returns directly to whoever calls proc2. Therefore, you should always be careful about pushing and popping data in a procedure, and verify that a one-to-one relationship exists between the pushes in your procedures and the corresponding pops.1
5.3.1 Activation Records
Whenever you call a procedure, the program associates certain information with that procedure call, including the return address, parameters, and automatic local variables, using a data structure called an activation record.2 The program creates an activation record when calling (activating) a procedure, and the data in the structure is organized in a manner identical to records.
Construction of an activation record begins in the code that calls a procedure. The caller makes room for the parameter data (if any) on the stack and copies the data onto the stack. Then the call instruction pushes the return address onto the stack. At this point, construction of the activation record continues within the procedure itself. The procedure pushes registers and other important state information and then makes room in the activation record for local variables. The procedure might also update the RBP register so that it points at the base address of the activation record.
To see what a traditional activation record looks like, consider the following C++ procedure declaration:
void ARDemo(unsigned i, int j, unsigned k)
{
int a;
float r;
char c;
bool b;
short w
.
.
.
}Whenever a program calls this ARDemo procedure, it begins by pushing the data for the parameters onto the stack. In the original C/C++ calling convention (ignoring the Microsoft ABI), the calling code pushes the parameters onto the stack in the opposite order that they appear in the parameter list, from right to left. Therefore, the calling code first pushes the value for the k parameter, then it pushes the value for the j parameter, and it finally pushes the data for the i parameter. After pushing the parameters, the program calls the ARDemo procedure. Immediately upon entry into the ARDemo procedure, the stack contains these four items arranged as shown in Figure 5-3. By pushing the parameters in the reverse order, they appear on the stack in the correct order (with the first parameter at the lowest address in memory).
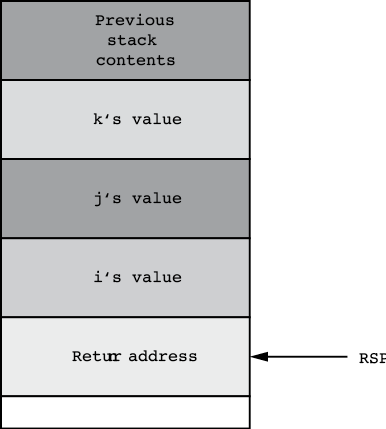
Figure 5-3: Stack organization immediately upon entry into ARDemo
The first few instructions in ARDemo will push the current value of RBP onto the stack and then copy the value of RSP into RBP.3 Next, the code drops the stack pointer down in memory to make room for the local variables. This produces the stack organization shown in Figure 5-4.
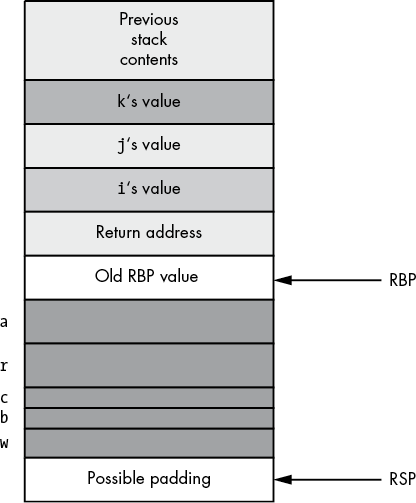
Figure 5-4: Activation record for ARDemo
5.3.1.1 Accessing Objects in the Activation Record
To access objects in the activation record, you must use offsets from the RBP register to the desired object. The two items of immediate interest to you are the parameters and the local variables. You can access the parameters at positive offsets from the RBP register; you can access the local variables at negative offsets from the RBP register, as Figure 5-5 shows.
Intel specifically reserves the RBP (Base Pointer) register for use as a pointer to the base of the activation record. This is why you should avoid using the RBP register for general calculations. If you arbitrarily change the value in the RBP register, you could lose access to the current procedure’s parameters and local variables.
The local variables are aligned on offsets that are equal to their native size (chars are aligned on 1-byte addresses, shorts/words are aligned on 2-byte addresses, longs/ints/unsigneds/dwords are aligned on 4-byte addresses, and so forth). In the ARDemo example, all of the locals just happen to be allocated on appropriate addresses (assuming a compiler allocates storage in the order of declaration).
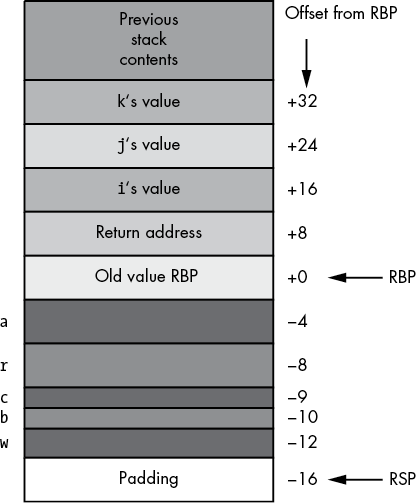
Figure 5-5: Offsets of objects in the ARDemo activation record
5.3.1.2 Using Microsoft ABI Parameter Conventions
The Microsoft ABI makes several modifications to the activation record model, in particular:
- The caller passes the first four parameters in registers rather than on the stack (though it must still reserve storage on the stack for those parameters).
- Parameters are always 8-byte values.
- The caller must reserve (at least) 32 bytes of parameter data on the stack, even if there are fewer than five parameters (plus 8 bytes for each additional parameter if there are five or more parameters).
- RSP must be 16-byte-aligned immediately before the
callinstruction pushes the return address onto the stack.
For more information, see “Microsoft ABI Notes” in Chapter 1. You must follow these conventions only when calling Windows or other Microsoft ABI–compliant code. For assembly language procedures that you write and call, you can use any convention you like.
5.3.2 The Assembly Language Standard Entry Sequence
The caller of a procedure is responsible for allocating storage for parameters on the stack and moving the parameter data to its appropriate location. In the simplest case, this just involves pushing the data onto the stack by using 64-bit push instructions. The call instruction pushes the return address onto the stack. It is the procedure’s responsibility to construct the rest of the activation record. You can accomplish this by using the following assembly language standard entry sequence code:
push rbp ; Save a copy of the old RBP value
mov rbp, rsp ; Get ptr to activation record into RBP
sub rsp, num_vars ; Allocate local variable storage plus paddingIf the procedure doesn’t have any local variables, the third instruction shown here, sub rsp, num_vars, isn’t necessary.
num_vars represents the number of bytes of local variables needed by the procedure, a constant that should be a multiple of 16 (so the RSP register remains aligned on a 16-byte boundary).4 If the number of bytes of local variables in the procedure is not a multiple of 16, you should round up the value to the next higher multiple of 16 before subtracting this constant from RSP. Doing so will slightly increase the amount of storage the procedure uses for local variables but will not otherwise affect the operation of the procedure.
If a Microsoft ABI–compliant program calls your procedure, the stack will be aligned on a 16-byte boundary immediately prior to the execution of the call instruction. As the return address adds 8 bytes to the stack, immediately upon entry into your procedure, the stack will be aligned on an (RSP mod 16) == 8 address (aligned on an 8-byte address but not on a 16-byte address). Pushing RBP onto the stack (to save the old value before copying RSP into RBP) adds another 8 bytes to the stack so that RSP is now 16-byte-aligned. Therefore, assuming the stack was 16-byte-aligned prior to the call, and the number you subtract from RSP is a multiple of 16, the stack will be 16-byte-aligned after allocating storage for local variables.
If you cannot ensure that RSP is 16-byte-aligned (RSP mod 16 == 8) upon entry into your procedure, you can always force 16-byte alignment by using the following sequence at the beginning of your procedure:
push rbp
mov rbp, rsp
sub rsp, num_vars ; Make room for local variables
and rsp, -16 ; Force qword stack alignmentThe –16 is equivalent to 0FFFF_FFFF_FFFF_FFF0h. The and instruction sequence forces the stack to be aligned on a 16-byte boundary (it reduces the value in the stack pointer so that it is a multiple of 16).
The ARDemo activation record has only 12 bytes of local storage. Therefore, subtracting 12 from RSP for the local variables will not leave the stack 16-byte-aligned. The and instruction in the preceding sequence, however, guarantees that RSP is 16-byte-aligned regardless of RSP’s value upon entry into the procedure (this adds in the padding bytes shown in Figure 5-5). The few bytes and CPU cycles needed to execute this instruction would pay off handsomely if RSP was not oword aligned. Of course, if you know that the stack was properly aligned before the call, you could dispense with the extra and instruction and simply subtract 16 from RSP rather than 12 (in other words, reserving 4 more bytes than the ARDemo procedure needs, to keep the stack aligned).
5.3.3 The Assembly Language Standard Exit Sequence
Before a procedure returns to its caller, it needs to clean up the activation record. Standard MASM procedures and procedure calls, therefore, assume that it is the procedure’s responsibility to clean up the activation record, although it is possible to share the cleanup duties between the procedure and the procedure’s caller.
If a procedure does not have any parameters, the exit sequence is simple. It requires only three instructions:
mov rsp, rbp ; Deallocate locals and clean up stack
pop rbp ; Restore pointer to caller's activation record
ret ; Return to the callerIn the Microsoft ABI (as opposed to pure assembly procedures), it is the caller’s responsibility to clean up any parameters pushed on the stack. Therefore, if you are writing a function to be called from C/C++ (or other Microsoft ABI–compliant code), your procedure doesn’t have to do anything at all about the parameters on the stack.
If you are writing procedures that will be called only from your assembly language programs, it is possible to have the callee (the procedure) rather than the caller clean up the parameters on the stack upon returning to the caller, using the following standard exit sequence:
mov rsp, rbp ; Deallocate locals and clean up stack
pop rbp ; Restore pointer to caller's activation record
ret parm_bytes ; Return to the caller and pop the parametersThe parm_bytes operand of the ret instruction is a constant that specifies the number of bytes of parameter data to remove from the stack after the return instruction pops the return address. For example, the ARDemo example code in the previous sections has three quad words reserved for the parameters (because we want to keep the stack qword aligned). Therefore, the standard exit sequence would take the following form:
mov rsp, rbp
pop rbp
ret 24If you do not specify a 16-bit constant operand to the ret instruction, the x86-64 will not pop the parameters off the stack upon return. Those parameters will still be sitting on the stack when you execute the first instruction following the call to the procedure. Similarly, if you specify a value that is too small, some of the parameters will be left on the stack upon return from the procedure. If the ret operand you specify is too large, the ret instruction will actually pop some of the caller’s data off the stack, usually with disastrous consequences.
By the way, Intel has added a special instruction to the instruction set to shorten the standard exit sequence: leave. This instruction copies RBP into RSP and then pops RBP. The following is equivalent to the standard exit sequence presented thus far:
leave
ret optional_constThe choice is up to you. Most compilers generate the leave instruction (because it’s shorter), so using it is the standard choice.
5.4 Local (Automatic) Variables
Procedures and functions in most high-level languages let you declare local variables. These are generally accessible only within the procedure; they are not accessible by the code that calls the procedure.
Local variables possess two special attributes in HLLs: scope and lifetime. The scope of an identifier determines where that identifier is visible (accessible) in the source file during compilation. In most HLLs, the scope of a procedure’s local variable is the body of that procedure; the identifier is inaccessible outside that procedure.
Whereas scope is a compile-time attribute of a symbol, lifetime is a runtime attribute. The lifetime of a variable is from that point when storage is first bound to the variable until the point where the storage is no longer available for that variable. Static objects (those you declare in the .data, .const, .data?, and .code sections) have a lifetime equivalent to the total runtime of the application. The program allocates storage for such variables when the program first loads into memory, and those variables maintain that storage until the program terminates.
Local variables (or, more properly, automatic variables) have their storage allocated upon entry into a procedure, and that storage is returned for other use when the procedure returns to its caller. The name automatic refers to the program automatically allocating and deallocating storage for the variable on procedure invocation and return.
A procedure can access any global .data, .data?, or .const object the same way the main program accesses such variables—by referencing the name (using the PC-relative addressing mode). Accessing global objects is convenient and easy. Of course, accessing global objects makes your programs harder to read, understand, and maintain, so you should avoid using global variables within procedures. Although accessing global variables within a procedure may sometimes be the best solution to a given problem, you likely won’t be writing such code at this point, so you should carefully consider your options before doing so.5
5.4.1 Low-Level Implementation of Automatic (Local) Variables
Your program accesses local variables in a procedure by using negative offsets from the activation record base address (RBP). Consider the following MASM procedure in Listing 5-6 (which admittedly doesn’t do much, other than demonstrate the use of local variables).
; Listing 5-6
; Accessing local variables.
option casemap:none
.code
; sdword a is at offset -4 from RBP.
; sdword b is at offset -8 from RBP.
; On entry, ECX and EDX contain values to store
; into the local variables a and b (respectively):
localVars proc
push rbp
mov rbp, rsp
sub rsp, 16 ; Make room for a and b
mov [rbp-4], ecx ; a = ECX
mov [rbp-8], edx ; b = EDX
; Additional code here that uses a and b:
mov rsp, rbp
pop rbp
ret
localVars endpListing 5-6: Sample procedure that accesses local variables
The standard entry sequence allocates 16 bytes of storage even though locals a and b require only 8. This keeps the stack 16-byte-aligned. If this isn’t necessary for a particular procedure, subtracting 8 would work just as well.
The activation record for localVars appears in Figure 5-6.
Of course, having to refer to the local variables by the offset from the RBP register is truly horrible. This code is not only difficult to read (is [RBP-4] the a or the b variable?) but also hard to maintain. For example, if you decide you no longer need the a variable, you’d have to go find every occurrence of [RBP-8] (accessing the b variable) and change it to [RBP-4].
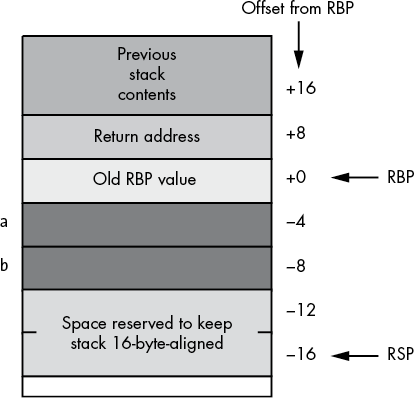
Figure 5-6: Activation record for the LocalVars procedure
A slightly better solution is to create equates for your local variable names. Consider the modification to Listing 5-6 shown here in Listing 5-7.
; Listing 5-7
; Accessing local variables #2.
option casemap:none
.code
; localVars - Demonstrates local variable access.
; sdword a is at offset -4 from RBP.
; sdword b is at offset -8 from RBP.
; On entry, ECX and EDX contain values to store
; into the local variables a and b (respectively):
a equ <[rbp-4]>
b equ <[rbp-8]>
localVars proc
push rbp
mov rbp, rsp
sub rsp, 16 ; Make room for a and b
mov a, ecx
mov b, edx
; Additional code here that uses a and b:
mov rsp, rbp
pop rbp
ret
localVars endpListing 5-7: Local variables using equates
This is considerably easier to read and maintain than the former program in Listing 5-6. It’s possible to improve on this equate system. For example, the following four equates are perfectly legitimate:
a equ <[rbp-4]>
b equ a-4
d equ b-4
e equ d-4MASM will associate [RBP-4] with a, [RBP-8] with b, [RBP-12] with d, and [RBP-16] with e. However, getting too crazy with fancy equates doesn’t pay; MASM provides a high-level-like declaration for local variables (and parameters) you can use if you really want your declarations to be as maintainable as possible.
5.4.2 The MASM Local Directive
Creating equates for local variables is a lot of work and error prone. It’s easy to specify the wrong offset when defining equates, and adding and removing local variables from a procedure is a headache. Fortunately, MASM provides a directive that lets you specify local variables, and MASM automatically fills in the offsets for the locals. That directive, local, uses the following syntax:
local list_of_declarationsThe list_of_declarations is a list of local variable declarations, separated by commas. A local variable declaration has two main forms:
identifier:type
identifier [elements]:typeHere, type is one of the usual MASM data types (byte, word, dword, and so forth), and identifier is the name of the local variable you are declaring. The second form declares local arrays, where elements is the number of array elements. elements must be a constant expression that MASM can resolve at assembly time.
local directives, if they appear in a procedure, must be the first statement(s) after a procedure declaration (the proc directive). A procedure may have more than one local statement; if there is more than one local directive, all must appear together after the proc declaration. Here’s a code snippet with examples of local variable declarations:
procWithLocals proc
local var1:byte, local2:word, dVar:dword
local qArray[4]:qword, rlocal:real4
local ptrVar:qword
local userTypeVar:userType
.
. ; Other statements in the procedure.
.
procWithLocals endpMASM automatically associates appropriate offsets with each variable you declare via the local directive. MASM assigns offsets to the variables by subtracting the variable’s size from the current offset (starting at zero) and then rounding down to an offset that is a multiple of the object’s size. For example, if userType is typedef’d to real8, MASM assigns offsets to the local variables in procWithLocals as shown in the following MASM listing output:
var1 . . . . . . . . . . . . . byte rbp - 00000001
local2 . . . . . . . . . . . . word rbp - 00000004
dVar . . . . . . . . . . . . . dword rbp - 00000008
qArray . . . . . . . . . . . . qword rbp - 00000028
rlocal . . . . . . . . . . . . dword rbp - 0000002C
ptrVar . . . . . . . . . . . . qword rbp - 00000034
userTypeVar . . . . . . . . . qword rbp - 0000003CIn addition to assigning an offset to each local variable, MASM associates the [RBP-constant] addressing mode with each of these symbols. Therefore, if you use a statement like mov ax, local2 in the procedure, MASM will substitute [RBP-4] for the symbol local2.
Of course, upon entry into the procedure, you must still allocate storage for the local variables on the stack; that is, you must still provide the code for the standard entry (and standard exit) sequence. This means you must add up all the storage needed for the local variables so you can subtract this value from RSP after moving RSP’s value into RBP. Once again, this is grunt work that could turn out to be a source of defects in the procedure (if you miscount the number of bytes of local variable storage), so you must take care when manually computing the storage requirements.
MASM does provide a solution (of sorts) for this problem: the option directive. You’ve seen the option casemap:none, option noscoped, and option scoped directives already; the option directive actually supports a wide array of arguments that control MASM’s behavior. Two option operands control procedure code generation when using the local directive: prologue and epilogue. These operands typically take the following two forms:
option prologue:PrologueDef
option prologue:none
option epilogue:EpilogueDef
option epilogue:noneBy default, MASM assumes prologue:none and epilogue:none. When you specify none as the prologue and epilogue values, MASM will not generate any extra code to support local variable storage allocation and deallocation in a procedure; you will be responsible for supplying the standard entry and exit sequences for the procedure.
If you insert the option prologue:PrologueDef (default prologue generation) and option epilogue:EpilogueDef (default epilogue generation) into your source file, all following procedures will automatically generate the appropriate standard entry and exit sequences for you (assuming local directives are in the procedure). MASM will quietly generate the standard entry sequence (the prologue) immediately after the last local directive (and before the first machine instruction) in a procedure, consisting of the usual standard entry sequence instructions
push rbp
mov rbp, rsp
sub rsp, local_sizewhere local_size is a constant specifying the number of local variables plus a (possible) additional amount to leave the stack aligned on a 16-byte boundary. (MASM usually assumes the stack was aligned on a mod 16 == 8 boundary prior to the push rbp instruction.)
For MASM’s automatically generated prologue code to work, the procedure must have exactly one entry point. If you define a global statement label as a second entry point, MASM won’t know that it is supposed to generate the prologue code at that point. Entering the procedure at that second entry point will create problems unless you explicitly include the standard entry sequence yourself. Moral of the story: procedures should have exactly one entry point.
Generating the standard exit sequence for the epilogue is a bit more problematic. Although it is rare for an assembly language procedure to have more than a single entry point, it’s common to have multiple exit points. After all, the exit point is controlled by the programmer’s placement of a ret instruction, not by a directive (like endp). MASM deals with the issue of multiple exit points by automatically translating any ret instruction it finds into the standard exit sequence:
leave
retAssuming, of course, that option epilogue:EpilogueDef is active.
You can control whether MASM generates prologues (standard entry sequences) and epilogues (standard exit sequences) independently of one another. So if you would prefer to write the leave instruction yourself (while having MASM generate the standard entry sequence), you can.
One final note about the prologue: and epilogue: options. In addition to specifying prologue:PrologueDef and epilogue:EpilogueDef, you can also supply a macro identifier after the prologue: or epilogue: options. If you supply a macro identifier, MASM will expand that macro for the standard entry or exit sequence. For more information on macros, see “Macros and the MASM Compile-Time Language” in Chapter 13.
Most of the example programs throughout the remainder of this book continue to use textequ declarations for local variables rather than the local directive to make the use of the [RBP-constant] addressing mode and local variable offsets more explicit.
5.4.3 Automatic Allocation
One big advantage to automatic storage allocation is that it efficiently shares a fixed pool of memory among several procedures. For example, say you call three procedures in a row, like so:
call ProcA
call ProcB
call ProcCThe first procedure (ProcA in this code) allocates its local variables on the stack. Upon return, ProcA deallocates that stack storage. Upon entry into ProcB, the program allocates storage for ProcB’s local variables by using the same memory locations just freed by ProcA. Likewise, when ProcB returns and the program calls ProcC, ProcC uses the same stack space for its local variables that ProcB recently freed up. This memory reuse makes efficient use of the system resources and is probably the greatest advantage to using automatic variables.
Now that you’ve seen how assembly language allocates and deallocates storage for local variables, it’s easy to understand why automatic variables do not maintain their values between two calls to the same procedure. Once the procedure returns to its caller, the storage for the automatic variable is lost, and, therefore, the value is lost as well. Thus, you must always assume that a local var object is uninitialized upon entry into a procedure. If you need to maintain the value of a variable between calls to a procedure, you should use one of the static variable declaration types.
5.5 Parameters
Although many procedures are totally self-contained, most require input data and return data to the caller. Parameters are values that you pass to and from a procedure. In straight assembly language, passing parameters can be a real chore.
The first thing to consider when discussing parameters is how we pass them to a procedure. If you are familiar with Pascal or C/C++, you’ve probably seen two ways to pass parameters: pass by value and pass by reference. Anything that can be done in an HLL can be done in assembly language (obviously, as HLL code compiles into machine code), but you have to provide the instruction sequence to access those parameters in an appropriate fashion.
Another concern you will face when dealing with parameters is where you pass them. There are many places to pass parameters: in registers, on the stack, in the code stream, in global variables, or in a combination of these. This chapter covers several of the possibilities.
5.5.1 Pass by Value
A parameter passed by value is just that—the caller passes a value to the procedure. Pass-by-value parameters are input-only parameters. You can pass them to a procedure, but the procedure cannot return values through them. Consider this C/C++ function call:
CallProc(I);If you pass I by value, CallProc() does not change the value of I, regardless of what happens to the parameter inside CallProc().
Because you must pass a copy of the data to the procedure, you should use this method only for passing small objects like bytes, words, double words, and quad words. Passing large arrays and records by value is inefficient (because you must create and pass a copy of the object to the procedure).6
5.5.2 Pass by Reference
To pass a parameter by reference, you must pass the address of a variable rather than its value. In other words, you must pass a pointer to the data. The procedure must dereference this pointer to access the data. Passing parameters by reference is useful when you must modify the actual parameter or when you pass large data structures between procedures. Because pointers on the x86-64 are 64 bits wide, a parameter that you pass by reference will consist of a quad-word value.
You can compute the address of an object in memory in two common ways: the offset operator or the lea instruction. You can use the offset operator to take the address of any static variable you’ve declared in your .data, .data?, .const, or .code sections. Listing 5-8 demonstrates how to obtain the address of a static variable (staticVar) and pass that address to a procedure (someFunc) in the RCX register.
; Listing 5-8
; Demonstrate obtaining the address
; of a static variable using offset
; operator.
option casemap:none
.data
staticVar dword ?
.code
externdef someFunc:proc
getAddress proc
mov rcx, offset staticVar
call someFunc
ret
getAddress endp
endListing 5-8: Using the offset operator to obtain the address of a static variable
Using the offset operator raises a couple of issues. First of all, it can compute the address of only a static variable; you cannot obtain the address of an automatic (local) variable or parameter, nor can you compute the address of a memory reference involving a complex memory addressing mode (for example, [RBX+RDX*1-5]). Another problem is that an instruction like mov rcx, offset staticVar assembles into a large number of bytes (because the offset operator returns a 64-bit constant). If you look at the assembly listing MASM produces (with the /Fl command line option), you can see how big this instruction is:
00000000 48/ B9 mov rcx, offset staticVar
0000000000000000 R
0000000A E8 00000000 E call someFuncAs you can see here, the mov instruction is 10 (0Ah) bytes long.
You’ve seen numerous examples of the second way to obtain the address of a variable: the lea instruction (for example, when loading the address of a format string into RCX prior to calling printf()). Listing 5-9 shows the example in Listing 5-8 recoded to use the lea instruction.
; Listing 5-9
; Demonstrate obtaining the address
; of a variable using the lea instruction.
option casemap:none
.data
staticVar dword ?
.code
externdef someFunc:proc
getAddress proc
lea rcx, staticVar
call someFunc
ret
getAddress endp
endListing 5-9: Obtaining the address of a variable using the lea instruction
Looking at the listing MASM produces for this code, we find that the lea instruction is only 7 bytes long:
00000000 48/ 8D 0D lea rcx, staticVar
00000000 R
00000007 E8 00000000 E call someFuncSo, if nothing else, your programs will be shorter if you use the lea instruction rather than the offset operator.
Another advantage to using lea is that it will accept any memory addressing mode, not just the name of a static variable. For example, if staticVar were an array of 32-bit integers, you could load the current element address, indexed by the RDX register, in RCX by using an instruction such as this:
lea rcx, staticVar[rdx*4] ; Assumes LARGEADDRESSAWARE:NOPass by reference is usually less efficient than pass by value. You must dereference all pass-by-reference parameters on each access; this is slower than simply using a value because it typically requires at least two instructions. However, when passing a large data structure, pass by reference is faster because you do not have to copy the large data structure before calling the procedure. Of course, you’d probably need to access elements of that large data structure (for example, an array) by using a pointer, so little efficiency is lost when you pass large arrays by reference.
5.5.3 Low-Level Parameter Implementation
A parameter-passing mechanism is a contract between the caller and the callee (the procedure). Both parties have to agree on where the parameter data will appear and what form it will take (for example, value or address). If your assembly language procedures are being called only by other assembly language code that you’ve written, you control both sides of the contract negotiation and get to decide where and how you’re going to pass parameters.
However, if external code is calling your procedure, or your procedure is calling external code, your procedure will have to adhere to whatever calling convention that external code uses. On 64-bit Windows systems, that calling convention will, undoubtedly, be the Windows ABI.
Before discussing the Windows calling conventions, we’ll consider the situation of calling code that you’ve written (and, therefore, have complete control over the calling conventions). The following sections provide insight into the various ways you can pass parameters in pure assembly language code (without the overhead associated with the Microsoft ABI).
5.5.3.1 Passing Parameters in Registers
Having touched on how to pass parameters to a procedure, the next thing to discuss is where to pass parameters. This depends on the size and number of those parameters. If you are passing a small number of parameters to a procedure, the registers are an excellent place to pass them. If you are passing a single parameter to a procedure, you should use the registers listed in Table 5-1 for the accompanying data types.
Table 5-1: Parameter Location by Size
| Data size | Pass in this register |
| Byte | CL |
| Word | CX |
| Double word | ECX |
| Quad word | RCX |
This is not a hard-and-fast rule. However, these registers are convenient because they mesh with the first parameter register in the Microsoft ABI (which is where most people will pass a single parameter).
If you are passing several parameters to a procedure in the x86-64’s registers, you should probably use up the registers in the following order:
First Last
RCX, RDX, R8, R9, R10, R11, RAX, XMM0/YMM0-XMM5/YMM5In general, you should pass integer and other non-floating-point values in the general-purpose registers, and floating-point values in the XMMx/YMMx registers. This is not a hard requirement, but Microsoft reserves these registers for passing parameters and for local variables (volatile), so using these registers to pass parameters won’t mess with Microsoft ABI nonvolatile registers. Of course, if you intend to have Microsoft ABI–compliant code call your procedure, you must exactly observe the Microsoft calling conventions (see “Calling Conventions and the Microsoft ABI” on page 261).
Of course, if you’re writing pure assembly language code (no calls to or from any code you didn’t write), you can use most of the general-purpose registers as you see fit (RSP is an exception, and you should avoid RBP, but the others are fair game). Ditto for the XMM/YMM registers.
As an example, consider the strfill(s,c) procedure that copies the character c (passed by value in AL) to each character position in s (passed by reference in RDI) up to a zero-terminating byte (Listing 5-10).
; Listing 5-10
; Demonstrate passing parameters in registers.
option casemap:none
.data
staticVar dword ?
.code
externdef someFunc:proc
; strfill - Overwrites the data in a string with a character.
; RDI - Pointer to zero-terminated string
; (for example, a C/C++ string).
; AL - Character to store into the string.
strfill proc
push rdi ; Preserve RDI because it changes
; While we haven't reached the end of the string:
whlNot0: cmp byte ptr [rdi], 0
je endOfStr
; Overwrite character in string with the character
; passed to this procedure in AL:
mov [rdi], al
; Move on to the next character in the string and
; repeat this process:
inc rdi
jmp whlNot0
endOfStr: pop rdi
ret
strfill endp
endListing 5-10: Passing parameters in registers to the strfill procedure
To call the strfill procedure, you would load the address of the string data into RDI and the character value into AL prior to the call. The following code fragment demonstrates a typical call to strfill:
lea rdi, stringData ; Load address of string into RDI
mov al, ' ' ; Fill string with spaces
call strfillThis code passes the string by reference and the character data by value.
5.5.3.2 Passing Parameters in the Code Stream
Another place where you can pass parameters is in the code stream immediately after the call instruction. Consider the following print routine that prints a literal string constant to the standard output device:
call print
byte "This parameter is in the code stream.",0Normally, a subroutine returns control to the first instruction immediately following the call instruction. Were that to happen here, the x86-64 would attempt to interpret the ASCII codes for "This..." as an instruction. This would produce undesirable results. Fortunately, you can skip over this string before returning from the subroutine.
So how do you gain access to these parameters? Easy. The return address on the stack points at them. Consider the implementation of print appearing in Listing 5-11.
; Listing 5-11
; Demonstration passing parameters in the code stream.
option casemap:none
nl = 10
stdout = -11
.const
ttlStr byte "Listing 5-11", 0
.data
soHandle qword ?
bWritten dword ?
.code
; Magic equates for Windows API calls:
extrn __imp_GetStdHandle:qword
extrn __imp_WriteFile:qword
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; Here's the print procedure.
; It expects a zero-terminated string
; to follow the call to print.
print proc
push rbp
mov rbp, rsp
and rsp, -16 ; Ensure stack is 16-byte-aligned
sub rsp, 48 ; Set up stack for MS ABI
; Get the pointer to the string immediately following the
; call instruction and scan for the zero-terminating byte.
mov rdx, [rbp+8] ; Return address is here
lea r8, [rdx-1] ; R8 = return address - 1
search4_0: inc r8 ; Move on to next char
cmp byte ptr [R8], 0 ; At end of string?
jne search4_0
; Fix return address and compute length of string:
inc r8 ; Point at new return address
mov [rbp+8], r8 ; Save return address
sub r8, rdx ; Compute string length
dec r8 ; Don't include 0 byte
; Call WriteFile to print the string to the console:
; WriteFile(fd, bufAdrs, len, &bytesWritten);
; Note: pointer to the buffer (string) is already
; in RDX. The len is already in R8. Just need to
; load the file descriptor (handle) into RCX:
mov rcx, soHandle ; Zero-extends!
lea r9, bWritten ; Address of "bWritten" in R9
call __imp_WriteFile
leave
ret
print endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 40
; Call getStdHandle with "stdout" parameter
; in order to get the standard output handle
; we can use to call write. Must set up
; soHandle before first call to print procedure.
mov ecx, stdout ; Zero-extends!
call __imp_GetStdHandle
mov soHandle, rax ; Save handle
; Demonstrate passing parameters in code stream
; by calling the print procedure:
call print
byte "Hello, world!", nl, 0
; Clean up, as per Microsoft ABI:
leave
ret ; Returns to caller
asmMain endp
end Listing 5-11: Print procedure implementation (using code stream parameters)
One quick note about a machine idiom in Listing 5-11. The instruction
lea r8, [rdx-1]isn’t actually loading an address into R8, per se. This is really an arithmetic instruction that is computing R8 = RDX – 1 (with a single instruction rather than two as would normally be required). This is a common usage of the lea instruction in assembly language programs. Therefore, it’s a little programming trick that you should become comfortable with.
Besides showing how to pass parameters in the code stream, the print routine also exhibits another concept: variable-length parameters. The string following the call can be any practical length. The zero-terminating byte marks the end of the parameter list.
We have two easy ways to handle variable-length parameters: either use a special terminating value (like 0) or pass a special length value that tells the subroutine the number of parameters you are passing. Both methods have their advantages and disadvantages.
Using a special value to terminate a parameter list requires that you choose a value that never appears in the list. For example, print uses 0 as the terminating value, so it cannot print the NUL character (whose ASCII code is 0). Sometimes this isn’t a limitation. Specifying a length parameter is another mechanism you can use to pass a variable-length parameter list. While this doesn’t require any special codes, or limit the range of possible values that can be passed to a subroutine, setting up the length parameter and maintaining the resulting code can be a real nightmare.8
Despite the convenience afforded by passing parameters in the code stream, passing parameters there has disadvantages. First, if you fail to provide the exact number of parameters the procedure requires, the subroutine will get confused. Consider the print example. It prints a string of characters up to a zero-terminating byte and then returns control to the first instruction following that byte. If you leave off the zero-terminating byte, the print routine happily prints the following opcode bytes as ASCII characters until it finds a zero byte. Because zero bytes often appear in the middle of an instruction, the print routine might return control into the middle of another instruction, which will probably crash the machine.
Inserting an extra 0, which occurs more often than you might think, is another problem programmers have with the print routine. In such a case, the print routine would return upon encountering the first zero byte and attempt to execute the following ASCII characters as machine code. Problems notwithstanding, however, the code stream is an efficient place to pass parameters whose values do not change.
5.5.3.3 Passing Parameters on the Stack
Most high-level languages use the stack to pass a large number of parameters because this method is fairly efficient. Although passing parameters on the stack is slightly less efficient than passing parameters in registers, the register set is limited (especially if you’re limiting yourself to the four registers the Microsoft ABI sets aside for this purpose), and you can pass only a few value or reference parameters through registers. The stack, on the other hand, allows you to pass a large amount of parameter data without difficulty. This is the reason that most programs pass their parameters on the stack (at least, when passing more than about three to six parameters).
To manually pass parameters on the stack, push them immediately before calling the subroutine. The subroutine then reads this data from the stack memory and operates on it appropriately. Consider the following high-level language function call:
CallProc(i,j,k);Back in the days of 32-bit assembly language, you could have passed these parameters to CallProc by using an instruction sequence such as the following:
push k ; Assumes i, j, and k are all 32-bit
push j ; variables
push i
call CallProcUnfortunately, with the advent of the x86-64 64-bit CPU, the 32-bit push instruction was removed from the instruction set (the 64-bit push instruction replaced it). If you want to pass parameters to a procedure by using the push instruction, they must be 64-bit operands.9
Because keeping RSP aligned on an appropriate boundary (8 or 16 bytes) is crucial, the Microsoft ABI simply requires that every parameter consume 8 bytes on the stack, and thus doesn’t allow larger arguments on the stack. If you’re controlling both sides of the parameter contract (caller and callee), you can pass larger arguments to your procedures. However, it is a good idea to ensure that all parameter sizes are a multiple of 8 bytes.
One simple solution is to make all your variables qword objects. Then you can directly push them onto the stack by using the push instruction prior to calling a procedure. However, not all objects fit nicely into 64 bits (characters, for example). Even those objects that could be 64 bits (for example, integers) often don’t require the use of so much storage.
One sneaky way to use the push instruction on smaller objects is to use type coercion. Consider the following calling sequence for CallProc:
push qword ptr k
push qword ptr j
push qword ptr i
call CallProcThis sequence pushes the 64-bit values starting at the addresses associated with variables i, j, and k, regardless of the size of these variables. If the i, j, and k variables are smaller objects (perhaps 32-bit integers), these push instructions will push their values onto the stack along with additional data beyond these variables. As long as CallProc treats these parameter values as their actual size (say, 32 bits) and ignores the HO bits pushed for each argument onto the stack, this will usually work out properly.
Pushing extra data beyond the bounds of the variable onto the stack creates one possible problem. If the variable is at the very end of a page in memory and the following page is not readable, then pushing data beyond the variable may attempt to push data from that next memory page, resulting in a memory access violation (which will crash your program). Therefore, if you use this technique, you must ensure that such variables do not appear at the very end of a memory page (with the possibility that the next page in memory is inaccessible). The easiest way to do this is to make sure the variables you push on the stack in this fashion are never the last variables you declare in your data sections; for example:
i dword ?
j dword ?
k dword ?
pad qword ? ; Ensures that there are at least 64 bits
; beyond the k variableWhile pushing extra data beyond a variable will work, it’s still a questionable programming practice. A better technique is to abandon the push instructions altogether and use a different technique to move the parameter data onto the stack.
Another way to “push” data onto the stack is to drop the RSP register down an appropriate amount in memory and then simply move data onto the stack by using a mov (or similar) instruction. Consider the following calling sequence for CallProc:
sub rsp, 12
mov eax, k
mov [rsp+8], eax
mov eax, j
mov [rsp+4], eax
mov eax, i
mov [rsp], eax
call CallProcAlthough this takes twice as many instructions as the previous examples (eight versus four), this sequence is safe (no possibility of accessing inaccessible memory pages). Furthermore, it pushes exactly the amount of data needed for the parameters onto the stack (32 bits for each object, for a total of 12 bytes).
The major problem with this approach is that it is a really bad idea to have an address in the RSP register that is not aligned on an 8-byte boundary. In the worst case, having a nonaligned (to 8 bytes) stack will crash your program; in the very best case, it will affect the performance of your program. So even if you want to pass the parameters as 32-bit integers, you should always allocate a multiple of 8 bytes for parameters on the stack prior to a call. The previous example would be encoded as follows:
sub rsp, 16 ; Allocate a multiple of 8 bytes
mov eax, k
mov [rsp+8], eax
mov eax, j
mov [rsp+4], eax
mov eax, i
mov [rsp], eax
call CallProcNote that CallProc will simply ignore the extra 4 bytes allocated on the stack in this fashion (don’t forget to remove this extra storage from the stack on return).
To satisfy the requirement of the Microsoft ABI (and, in fact, of most application binary interfaces for the x86-64 CPUs) that each parameter consume exactly 8 bytes (even if their native data size is smaller), you can use the following code (same number of instructions, just uses a little more stack space):
sub rsp, 24 ; Allocate a multiple of 8 bytes
mov eax, k
mov [rsp+16], eax
mov eax, j
mov [rsp+8], eax
mov eax, i
mov [rsp], eax
call CallProcThe mov instructions spread out the data on 8-byte boundaries. The HO dword of each 64-bit entry on the stack will contain garbage (whatever data was in stack memory prior to this sequence). That’s okay; the CallProc procedure (presumably) will ignore that extra data and operate only on the LO 32 bits of each parameter value.
Upon entry into CallProc, using this sequence, the x86-64’s stack looks like Figure 5-7.
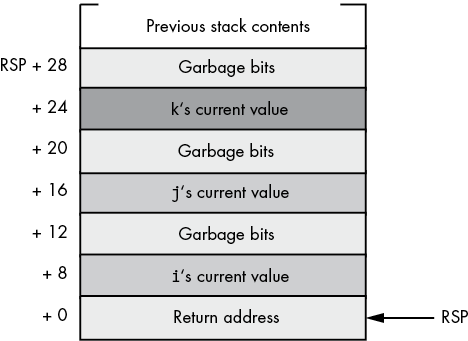
Figure 5-7: Stack layout upon entry into CallProc
If your procedure includes the standard entry and exit sequences, you may directly access the parameter values in the activation record by indexing off the RBP register. Consider the layout of the activation record for CallProc that uses the following declaration:
CallProc proc
push rbp ; This is the standard entry sequence
mov rbp, rsp ; Get base address of activation record into RBP
.
.
.
leave
ret 24Assuming you’ve pushed three quad-word parameters onto the stack, it should look something like Figure 5-8 immediately after the execution of mov rbp, rsp in CallProc.
Now you can access the parameters by indexing off the RBP register:
mov eax, [rbp+32] ; Accesses the k parameter
mov ebx, [rbp+24] ; Accesses the j parameter
mov ecx, [rbp+16] ; Accesses the i parameter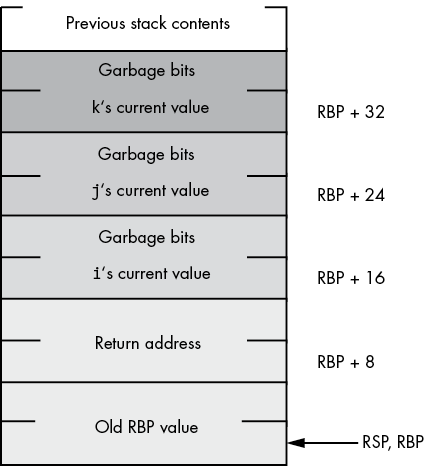
Figure 5-8: Activation record for CallProc after standard entry sequence execution
5.5.3.4 Accessing Value Parameters on the Stack
Accessing parameters passed by value is no different from accessing a local variable object. One way to accomplish this is by using equates, as was demonstrated for local variables earlier. Listing 5-12 provides an example program whose procedure accesses a parameter that the main program passes to it by value.
; Listing 5-12
; Accessing a parameter on the stack.
option casemap:none
nl = 10
stdout = -11
.const
ttlStr byte "Listing 5-12", 0
fmtStr1 byte "Value of parameter: %d", nl, 0
.data
value1 dword 20
value2 dword 30
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
theParm equ <[rbp+16]>
ValueParm proc
push rbp
mov rbp, rsp
sub rsp, 32 ; "Magic" instruction
lea rcx, fmtStr1
mov edx, theParm
call printf
leave
ret
ValueParm endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 40
mov eax, value1
mov [rsp], eax ; Store parameter on stack
call ValueParm
mov eax, value2
mov [rsp], eax
call ValueParm
; Clean up, as per Microsoft ABI:
leave
ret ; Returns to caller
asmMain endp
endListing 5-12: Demonstration of value parameters
Although you could access the value of theParm by using the anonymous address [RBP+16] within your code, using the equate in this fashion makes your code more readable and maintainable.
5.5.4 Declaring Parameters with the proc Directive
MASM provides another solution for declaring parameters for procedures using the proc directive. You can supply a list of parameters as operands to the proc directive, as follows:
proc_name proc parameter_listwhere parameter_list is a list of one or more parameter declarations separated by commas. Each parameter declaration takes the form
parm_name:typewhere parm_name is a valid MASM identifier, and type is one of the usual MASM types (proc, byte, word, dword, and so forth). With one exception, the parameter list declarations are identical to the local directive’s operands: the exception is that MASM doesn’t allow arrays as parameters. (MASM parameters assume that the Microsoft ABI is being used, and the Microsoft ABI allows only 64-bit parameters.)
The parameter declarations appearing as proc operands assume that a standard entry sequence is executed and that the program will access parameters off the RBP register, with the saved RBP and return address values at offsets 0 and 8 from the RBP register (so the first parameter will start at offset 16). MASM assigns offsets for each parameter that are 8 bytes apart (per the Microsoft ABI). As an example, consider the following parameter declaration:
procWithParms proc k:byte, j:word, i:dword
.
.
.
procWithParms endpk will have the offset [RBP+16], j will have the offset [RBP+24], and i will have the offset [RBP+32]. Again, the offsets are always 8 bytes, regardless of the parameter data type.
As per the Microsoft ABI, MASM will allocate storage on the stack for the first four parameters, even though you would normally pass these parameters in RCX, RDX, R8, and R9. These 32 bytes of storage (starting at RBP+16) are called shadow storage in Microsoft ABI nomenclature. Upon entry into the procedure, the parameter values do not appear in this shadow storage (instead, the values are in the registers). The procedure can save the register values in this preallocated storage, or it can use the shadow storage for any purpose it desires (such as for additional local variable storage). However, if the procedure refers to the parameter names declared in the proc operand field, expecting to access the parameter data, the procedure should store the values from these registers into that shadow storage (assuming the parameters were passed in the RCX, RDX, R8, and R9 registers). Of course, if you push these arguments on the stack prior to the call (in assembly language, ignoring the Microsoft ABI calling convention), then the data is already in place, and you don’t have to worry about shadow storage issues.
When calling a procedure whose parameters you declare in the operand field of a proc directive, don’t forget that MASM assumes you push the parameters onto the stack in the reverse order they appear in the parameter list, to ensure that the first parameter in the list is at the lowest memory address on the stack. For example, if you call the procWithParms procedure from the previous code snippet, you’d typically use code like the following to push the parameters:
mov eax, dwordValue
push rax ; Parms are always 64 bits
mov ax, wordValue
push rax
mov al, byteValue
push rax
call procWithParmsAnother possible solution (a few bytes longer, but often faster) is to use the following code:
sub rsp, 24 ; Reserve storage for parameters
mov eax, dwordValue ; i
mov [rsp+16], eax
mov ax, wordValue
mov [rsp+8], ax ; j
mov al, byteValue
mov [rsp], al ; k
call procWithParmsDon’t forget that if it is the callee’s responsibility to clean up the stack, you’d probably use an add rsp, 24 instruction after the preceding two sequences to remove the parameters from the stack. Of course, you can also have the procedure itself clean up the stack by specifying the number to add to RSP as a ret instruction operand, as explained earlier in this chapter.
5.5.5 Accessing Reference Parameters on the Stack
Because you pass the addresses of objects as reference parameters, accessing the reference parameters within a procedure is slightly more difficult than accessing value parameters because you have to dereference the pointers to the reference parameters.
In Listing 5-13, the RefParm procedure has a single pass-by-reference parameter. A pass-by-reference parameter is always a (64-bit) pointer to an object. To access the value associated with the parameter, this code has to load that quad-word address into a 64-bit register and access the data indirectly. The mov rax, theParm instruction in Listing 5-13 fetches this pointer into the RAX register, and then the procedure RefParm uses the [RAX] addressing mode to access the actual value of theParm.
; Listing 5-13
; Accessing a reference parameter on the stack.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 5-13", 0
fmtStr1 byte "Value of parameter: %d", nl, 0
.data
value1 dword 20
value2 dword 30
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
theParm equ <[rbp+16]>
RefParm proc
push rbp
mov rbp, rsp
sub rsp, 32 ; "Magic" instruction
lea rcx, fmtStr1
mov rax, theParm ; Dereference parameter
mov edx, [rax]
call printf
leave
ret
RefParm endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 40
lea rax, value1
mov [rsp], rax ; Store address on stack
call RefParm
lea rax, value2
mov [rsp], rax
call RefParm
; Clean up, as per Microsoft ABI:
leave
ret ; Returns to caller
asmMain endp
endListing 5-13: Accessing a reference parameter
Here are the build commands and program output for Listing 5-13:
C:\>build listing5-13
C:\>echo off
Assembling: listing5-13.asm
c.cpp
C:\>listing5-13
Calling Listing 5-13:
Value of parameter: 20
Value of parameter: 30
Listing 5-13 terminatedAs you can see, accessing (small) pass-by-reference parameters is a little less efficient than accessing value parameters because you need an extra instruction to load the address into a 64-bit pointer register (not to mention you have to reserve a 64-bit register for this purpose). If you access reference parameters frequently, these extra instructions can really begin to add up, reducing the efficiency of your program. Furthermore, it’s easy to forget to dereference a reference parameter and use the address of the value in your calculations. Therefore, unless you really need to affect the value of the actual parameter, you should use pass by value to pass small objects to a procedure.
Passing large objects, like arrays and records, is where using reference parameters becomes efficient. When passing these objects by value, the calling code has to make a copy of the actual parameter; if it is a large object, the copy process can be inefficient. Because computing the address of a large object is just as efficient as computing the address of a small scalar object, no efficiency is lost when passing large objects by reference. Within the procedure, you must still dereference the pointer to access the object, but the efficiency loss due to indirection is minimal when you contrast this with the cost of copying that large object. The program in Listing 5-14 demonstrates how to use pass by reference to initialize an array of records.
; Listing 5-14
; Passing a large object by reference.
option casemap:none
nl = 10
NumElements = 24
Pt struct
x byte ?
y byte ?
Pt ends
.const
ttlStr byte "Listing 5-14", 0
fmtStr1 byte "RefArrayParm[%d].x=%d ", 0
fmtStr2 byte "RefArrayParm[%d].y=%d", nl, 0
.data
index dword ?
Pts Pt NumElements dup ({})
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
ptArray equ <[rbp+16]>
RefAryParm proc
push rbp
mov rbp, rsp
mov rdx, ptArray
xor rcx, rcx ; RCX = 0
; While ECX < NumElements, initialize each
; array element. x = ECX/8, y = ECX % 8.
ForEachEl: cmp ecx, NumElements
jnl LoopDone
mov al, cl
shr al, 3 ; AL = ECX / 8
mov [rdx][rcx*2].Pt.x, al
mov al, cl
and al, 111b ; AL = ECX % 8
mov [rdx][rcx*2].Pt.y, al
inc ecx
jmp ForEachEl
LoopDone: leave
ret
RefAryParm endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 40
; Initialize the array of points:
lea rax, Pts
mov [rsp], rax ; Store address on stack
call RefAryParm
; Display the array:
mov index, 0
dispLp: cmp index, NumElements
jnl dispDone
lea rcx, fmtStr1
mov edx, index ; Zero-extends!
lea r8, Pts ; Get array base
movzx r8, [r8][rdx*2].Pt.x ; Get x field
call printf
lea rcx, fmtStr2
mov edx, index ; Zero-extends!
lea r8, Pts ; Get array base
movzx r8, [r8][rdx*2].Pt.y ; Get y field
call printf
inc index
jmp dispLp
; Clean up, as per Microsoft ABI:
dispDone:
leave
ret ; Returns to caller
asmMain endp
endListing 5-14: Passing an array of records by referencing
Here are the build commands and output for Listing 5-14:
C:\>build listing5-14
C:\>echo off
Assembling: listing5-14.asm
c.cpp
C:\>listing5-14
Calling Listing 5-14:
RefArrayParm[0].x=0 RefArrayParm[0].y=0
RefArrayParm[1].x=0 RefArrayParm[1].y=1
RefArrayParm[2].x=0 RefArrayParm[2].y=2
RefArrayParm[3].x=0 RefArrayParm[3].y=3
RefArrayParm[4].x=0 RefArrayParm[4].y=4
RefArrayParm[5].x=0 RefArrayParm[5].y=5
RefArrayParm[6].x=0 RefArrayParm[6].y=6
RefArrayParm[7].x=0 RefArrayParm[7].y=7
RefArrayParm[8].x=1 RefArrayParm[8].y=0
RefArrayParm[9].x=1 RefArrayParm[9].y=1
RefArrayParm[10].x=1 RefArrayParm[10].y=2
RefArrayParm[11].x=1 RefArrayParm[11].y=3
RefArrayParm[12].x=1 RefArrayParm[12].y=4
RefArrayParm[13].x=1 RefArrayParm[13].y=5
RefArrayParm[14].x=1 RefArrayParm[14].y=6
RefArrayParm[15].x=1 RefArrayParm[15].y=7
RefArrayParm[16].x=2 RefArrayParm[16].y=0
RefArrayParm[17].x=2 RefArrayParm[17].y=1
RefArrayParm[18].x=2 RefArrayParm[18].y=2
RefArrayParm[19].x=2 RefArrayParm[19].y=3
RefArrayParm[20].x=2 RefArrayParm[20].y=4
RefArrayParm[21].x=2 RefArrayParm[21].y=5
RefArrayParm[22].x=2 RefArrayParm[22].y=6
RefArrayParm[23].x=2 RefArrayParm[23].y=7
Listing 5-14 terminatedAs you can see from this example, passing large objects by reference is very efficient.
5.6 Calling Conventions and the Microsoft ABI
Back in the days of 32-bit programs, different compilers and languages typically used completely different parameter-passing conventions. As a result, a program written in Pascal could not call a C/C++ function (at least, using the native Pascal parameter-passing conventions). Similarly, C/C++ programs couldn’t call FORTRAN, or BASIC, or functions written in other languages, without special help from the programmer. It was literally a Tower of Babel situation, as the languages were incompatible with one another.10
To resolve these problems, CPU manufacturers, such as Intel, devised a set of protocols known as the application binary interface (ABI) to provide conformity to procedure calls. Languages that conformed to the CPU manufacturer’s ABI were able to call functions and procedures written in other languages that also conformed to the same ABI. This brought a modicum of sanity to the world of programming language interoperability.
For programs running under Windows, Microsoft took a subset of the Intel ABI and created the Microsoft calling convention (which most people call the Microsoft ABI). The next section covers the Microsoft calling conventions in detail. However, first it’s worthwhile to discuss many of the other calling conventions that existed prior to the Microsoft ABI.11
One of the older formal calling conventions is the Pascal calling convention. In this convention, a caller pushes parameters on the stack in the order that they appear in the actual parameter list (from left to right). On the 80x86/x86-64 CPUs, where the stack grows down in memory, the first parameter winds up at the highest address on the stack, and the last parameter winds up at the lowest address on the stack.
While it might look like the parameters appear backward on the stack, the computer doesn’t really care. After all, the procedure will access the parameters by using a numeric offset, and it doesn’t care about the offset’s value.12 On the other hand, for simple compilers, it’s much easier to generate code that pushes the parameters in the order they appear in the source file, so the Pascal calling convention makes life a little easier for compiler writers (though optimizing compilers often rearrange the code anyway).
Another feature of the Pascal calling convention is that the callee (the procedure itself) is responsible for removing parameter data from the stack upon subroutine return. This localizes the cleanup code to the procedure so that parameter cleanup isn’t duplicated across every call to the procedure.
The big drawback to the Pascal calling sequence is that handling variable parameter lists is difficult. If one call to a procedure has three parameters, and a second call has four parameters, the offset to the first parameter will vary depending on the actual number of parameters. Furthermore, it’s more difficult (though certainly not impossible) for a procedure to clean up the stack after itself if the number of parameters varies. This is not an issue for Pascal programs, as standard Pascal does not allow user-written procedures and functions to have varying parameter lists. For languages like C/C++, however, this is an issue.
Because C (and other C-based programming languages) supports varying parameter lists (for example, the printf() function), C adopted a different calling convention: the C calling convention, also known as the cdecl calling convention. In C, the caller pushes parameters on the stack in the reverse order that they appear in the actual parameter list. So, it pushes the last parameter first and pushes the first parameter last. Because the stack is a LIFO data structure, the first parameter winds up at the lowest address on the stack (and at a fixed offset from the return address, typically right above it in memory; this is true regardless of how many actual parameters appear on the stack). Also, because C supports varying parameter lists, it is up to the caller to clean up the parameters on the stack after the return from the function.
The third common calling convention in use on 32-bit Intel machines, STDCALL, is basically a combination of the Pascal and C/C++ calling conventions. Parameters are passed right to left (as in C/C++). However, the callee is responsible for cleaning up the parameters on the stack before returning.
One problem with these three calling conventions is that they all use only memory to pass their parameters to a procedure. Of course, the most efficient place to pass parameters is in machine registers. This led to a fourth common calling convention known as the FASTCALL calling convention. In this convention, the calling program passes parameters in registers to a procedure. However, as registers are a limited resource on most CPUs, the FASTCALL calling convention typically passes only the first three to six parameters in registers. If more parameters are needed, the FASTCALL passes the remaining parameters on the stack (typically in reverse order, like the C/C++ and STDCALL calling conventions).
5.7 The Microsoft ABI and Microsoft Calling Convention
This chapter has repeatedly referred to the Microsoft ABI. Now it’s time to formally describe the Microsoft calling convention.
5.7.1 Data Types and the Microsoft ABI
As noted in “Microsoft ABI Notes” in Chapters 1, 3, and 4, the native data type sizes are 1, 2, 4, and 8 bytes (see Table 1-6 in Chapter 1). All such variables should be aligned in memory on their native size.
For parameters, all procedure/function parameters must consume exactly 64 bits. If a data object is smaller than 64 bits, the HO bits of the parameter value (the bits beyond the actual parameter’s native size) are undefined (and not guaranteed to be zero). Procedures should access only the actual data bits for the parameter’s native type and ignore the HO bits.
If a parameter’s native type is larger than 64 bits, the Microsoft ABI requires the caller to pass the parameter by reference rather than by value (that is, the caller must pass the address of the data).
5.7.2 Parameter Locations
The Microsoft ABI uses a variant of the FASTCALL calling convention that requires the caller to pass the first four parameters in registers. Table 5-2 lists the register locations for these parameters.
Table 5-2: FASTCALL Parameter Locations
| Parameter | If scalar/reference | If floating point |
| 1 | RCX | XMM0 |
| 2 | RDX | XMM1 |
| 3 | R8 | XMM2 |
| 4 | R9 | XMM3 |
| 5 to n | On stack, right to left | On stack, right to left |
If the procedure has floating-point parameters, the calling convention skips the use of the general-purpose register for that same parameter location. Say you have the following C/C++ function:
void someFunc(int a, double b, char *c, double d)Then the Microsoft calling convention would expect the caller to pass a in (the LO 32 bits of) RCX, b in XMM1, a pointer to c in R8, and d in XMM3, skipping RDX, R9, XMM0, and XMM2. This rule has an exception: for vararg (variable number of parameters) or unprototyped functions, floating-point values must be duplicated in the corresponding general-purpose register (see https://docs.microsoft.com/en-us/cpp/build/x64-calling-convention?view=msvc-160#parameter-passing/).
Although the Microsoft calling convention passes the first four parameters in registers, it still requires the caller to allocate storage on the stack for these parameters (shadow storage).13 In fact, the Microsoft calling convention requires the caller to allocate storage for four parameters on the stack even if the procedure doesn’t have four parameters (or any parameters at all). The caller doesn’t need to copy the parameter data into this stack storage area—leaving the parameter data only in the registers is sufficient. However, that stack space must be present. Microsoft compilers assume the stack space is there and will use that stack space to save the register values (for example, if the procedure calls another procedure and needs to preserve the registers across that other call). Sometimes Microsoft’s compilers use this shadow storage as local variables.
If you’re calling an external function (such as a C/C++ library function) that adheres to the Microsoft calling convention and you do not allocate the shadow storage, the application will almost certainly crash.
5.7.3 Volatile and Nonvolatile Registers
As noted way back in Chapter 1, the Microsoft ABI declares certain registers to be volatile and others to be nonvolatile. Volatile means that a procedure can modify the contents of the register without preserving its value. Nonvolatile means that a procedure must preserve a register’s value if it modifies that value. Table 5-3 lists the registers and their volatility.
Table 5-3: Register Volatility
| Register | Volatile/nonvolatile |
| RAX | Volatile |
| RBX | Nonvolatile |
| RCX | Volatile |
| RDX | Volatile |
| RDI | Nonvolatile |
| RSI | Nonvolatile |
| RBP | Nonvolatile |
| RSP | Nonvolatile |
| R8 | Volatile |
| R9 | Volatile |
| R10 | Volatile |
| R11 | Volatile |
| R12 | Nonvolatile |
| R13 | Nonvolatile |
| R14 | Nonvolatile |
| R15 | Nonvolatile |
| XMM0/YMM0 | Volatile |
| XMM1/YMM1 | Volatile |
| XMM2/YMM2 | Volatile |
| XMM3/YMM3 | Volatile |
| XMM4/YMM4 | Volatile |
| XMM5/YMM5 | Volatile |
| XMM6/YMM6 | XMM6 Nonvolatile, upper half of YMM6 volatile |
| XMM7/YMM7 | XMM7 Nonvolatile, upper half of YMM7 volatile |
| XMM8/YMM8 | XMM8 Nonvolatile, upper half of YMM8 volatile |
| XMM9/YMM9 | XMM9 Nonvolatile, upper half of YMM9 volatile |
| XMM10/YMM10 | XMM10 Nonvolatile, upper half of YMM10 volatile |
| XMM11/YMM11 | XMM11 Nonvolatile, upper half of YMM11 volatile |
| XMM12/YMM12 | XMM12 Nonvolatile, upper half of YMM12 volatile |
| XMM13/YMM13 | XMM13 Nonvolatile, upper half of YMM13 volatile |
| XMM14/YMM14 | XMM14 Nonvolatile, upper half of YMM14 volatile |
| XMM15/YMM15 | XMM15 Nonvolatile, upper half of YMM15 volatile |
| FPU | Volatile, but FPU stack must be empty upon return |
| Direction flag | Must be cleared upon return |
It is perfectly reasonable to use nonvolatile registers within a procedure. However, you must preserve those register values so that they are unchanged upon return from a function. If you’re not using the shadow storage for anything else, this is a good place to save and restore nonvolatile register values during a procedure call; for example:
someProc proc
push rbp
mov rbp, rsp
mov [rbp+16], rbx ; Save RBX in parm 1's shadow
.
. ; Procedure's code
.
mov rbx, [rbp+16] ; Restore RBX from shadow
leave
ret
someProc endpOf course, if you’re using the shadow storage for another purpose, you can always save nonvolatile register values in local variables or can even push and pop the register values:
someProc proc ; Save RBX via push
push rbx ; Note that this affects parm offsets
push rbp
mov rbp, rsp
.
. ; Procedure's code
.
leave
pop rbx ; Restore RBX from stack
ret
someProc endp
someProc2 proc ; Save RBX in a local
push rbp
mov rbp, rsp
sub rsp, 16 ; Keep stack aligned
mov [rbp-8], rbx ; Save RBX
.
. ; Procedure's code
.
mov rbx, [rbp-8] ; Restore RBX
leave
ret
someProc2 endp5.7.4 Stack Alignment
As I’ve mentioned many times now, the Microsoft ABI requires the stack to be aligned on a 16-byte boundary whenever you make a call to a procedure. When Windows transfers control to your assembly code (or when another Windows ABI–compliant code calls your assembly code), you’re guaranteed that the stack will be aligned on an 8-byte boundary that is not also a 16-byte boundary (because the return address consumed 8 bytes after the stack was 16-byte-aligned). If, within your assembly code, you don’t care about 16-byte alignment, you can do anything you like with the stack (however, you should keep it aligned on at least an 8-byte boundary).
On the other hand, if you ever plan on calling code that uses the Microsoft calling conventions, you need to be able to ensure that the stack is properly aligned before the call. There are two ways to do this: carefully manage any modifications to the RSP register after entry into your code (so you know the stack is 16-byte-aligned whenever you make a call), or force the stack to an appropriate alignment prior to making a call. Forcing alignment to 16 bytes is easily achieved using this instruction:
and rsp, -16However, you must execute this instruction before setting up parameters for a call. If you execute this instruction immediately before a call instruction (but after placing all the parameters on the stack), this could shift RSP down in memory, and then the parameters will not be at the expected offset upon entry into the procedure.
Suppose you don’t know the state of RSP and need to make a call to a procedure that expects five parameters (40 bytes, which is not a multiple of 16 bytes). Here’s a typical calling sequence you would use:
sub rsp, 40 ; Make room for 4 shadow parms plus a 5th parm
and rsp, -16 ; Guarantee RSP is now 16-byte-aligned
; Code to move four parameters into registers and the
; 5th parameter to location [RSP+32]:
mov rcx, parm1
mov rdx, parm2
mov r8, parm3
mov r9, parm4
mov rax, parm5
mov [rsp+32], rax
call procWith5ParmsThe only problem with this code is that it is hard to clean up the stack upon return (because you don’t know exactly how many bytes you reserved on the stack as a result of the and instruction). However, as you’ll see in the next section, you’ll rarely clean up the stack after an individual procedure call, so you don’t have to worry about the stack cleanup here.
5.7.5 Parameter Setup and Cleanup (or “What’s with These Magic Instructions?”)
The Microsoft ABI requires the caller to set up the parameters and then clean them up (remove them from the stack) upon return from the function. In theory, this means that a call to a Microsoft ABI–compliant function is going to look something like the following:
; Make room for parameters. parm_size is a constant
; with the number of bytes of parameters required
; (including 32 bytes for the shadow parameters).
sub rsp, parm_size
Code that copies parameters to the stack
call procedure
; Clean up the stack after the call:
add rsp, parm_sizeThis allocation and cleanup sequence has two problems. First, you have to repeat the sequence (sub rsp, parm_size and add rsp, parm_size) for every call in your program (which can be rather inefficient). Second, as you saw in the preceding section, sometimes aligning the stack to a 16-byte boundary forces you to adjust the stack downward by an unknown amount, so you don’t know how many bytes to add to RSP in order to clean up the stack.
If you have several calls sprinkled through a given procedure, you can optimize the process of allocating and deallocating parameters on the stack by doing this operation just once. To understand how this works, consider the following code sequence:
; 1st procedure call:
sub rsp, parm_size ; Allocate storage for proc1 parms
Code that copies parameters to the registers and stack
call proc1
add rsp, parm_size ; Clean up the stack
; 2nd procedure call:
sub rsp, parm_size2 ; Allocate storage for proc2 parms
Code that copies parameters to the registers and stack
call proc2
add rsp, parm_size2 ; Clean up the stackIf you study this code, you should be able to convince yourself that the first add and second sub are somewhat redundant. If you were to modify the first sub instruction to reduce the stack size by the greater of parm_size and parm_size2, and replace the final add instruction with this same value, you could eliminate the add and sub instructions appearing between the two calls:
; 1st procedure call:
sub rsp, max_parm_size ; Allocate storage for all parms
Code that copies parameters to the registers and stack for proc1
call proc1
Code that copies parameters to the registers and stack for proc2
call proc2
add rsp, max_parm_size ; Clean up the stackIf you determine the maximum number of bytes of parameters needed by all calls within your procedure, you can eliminate all the individual stack allocations and cleanups throughout the procedure (don’t forget, the minimum parameter size is 32 bytes, even if the procedure has no parameters at all, because of the shadow storage requirements).
It gets even better, though. If your procedure has local variables, you can combine the sub instruction that allocates local variables with the one that allocates storage for your parameters. Similarly, if you’re using the standard entry/exit sequence, the leave instruction at the end of your procedure will automatically deallocate all the parameters (as well as the local variables) when you exit your procedure.
Throughout this book, you’ve seen lots of “magic” add and subtract instructions that have been offered without much in the way of explanation. Now you know what those instructions have been doing: they’ve been allocating storage for local variables and all the parameter space for the procedures being called as well as keeping the stack 16-byte-aligned.
Here’s one last example of a procedure that uses the standard entry/exit procedure to set up locals and parameter space:
rbxSave equ [rbp-8]
someProc proc
push rbp
mov rbp, rsp
sub rsp, 48 ; Also leave stack 16-byte-aligned
mov rbxSave, rbx ; Preserve RBX
.
.
.
lea rcx, fmtStr
mov rdx, rbx ; Print value in RBX (presumably)
call printf
.
.
.
mov rbx, rbxSave ; Restore RBX
leave ; Clean up stack
ret
someProc endpHowever, if you use this trick to allocate storage for your procedures’ parameters, you will not be able to use the push instructions to move the data onto the stack. The storage has already been allocated on the stack for the parameters; you must use mov instructions to copy the data onto the stack (using the [RSP+constant] addressing mode) when copying the fifth and greater parameters.
5.8 Functions and Function Results
Functions are procedures that return a result to the caller. In assembly language, few syntactical differences exist between a procedure and a function, which is why MASM doesn’t provide a specific declaration for a function. Nevertheless, there are some semantic differences; although you can declare them the same way in MASM, you use them differently.
Procedures are a sequence of machine instructions that fulfill a task. The result of the execution of a procedure is the accomplishment of that activity. Functions, on the other hand, execute a sequence of machine instructions specifically to compute a value to return to the caller. Of course, a function can perform an activity as well, and procedures can undoubtedly compute values, but the main difference is that the purpose of a function is to return a computed result; procedures don’t have this requirement.
In assembly language, you don’t specifically define a function by using special syntax. To MASM, everything is a proc. A section of code becomes a function by virtue of the fact that the programmer explicitly decides to return a function result somewhere (typically in a register) via the procedure’s execution.
The x86-64’s registers are the most common place to return function results. The strlen() routine in the C Standard Library is a good example of a function that returns a value in one of the CPU’s registers. It returns the length of the string (whose address you pass as a parameter) in the RAX register.
By convention, programmers try to return 8-, 16-, 32-, and 64-bit (nonreal) results in the AL, AX, EAX, and RAX registers, respectively. This is where most high-level languages return these types of results, and it’s where the Microsoft ABI states that you should return function results. The exception is floating-point values. The Microsoft ABI states that you should return floating-point values in the XMM0 register.
Of course, there is nothing particularly sacred about the AL, AX, EAX, and RAX registers. You could return function results in any register if it is more convenient to do so. Of course, if you’re calling a Microsoft ABI–compliant function (such as strlen()), you have no choice but to expect the function’s return result in the RAX register (strlen() returns a 64-bit integer in RAX, for example).
If you need to return a function result that is larger than 64 bits, you obviously must return it somewhere other than in RAX (which can hold only 64-bit values). For values slightly larger than 64 bits (for example, 128 bits or maybe even as many as 256 bits), you can split the result into pieces and return those parts in two or more registers. It is common to see functions returning 128-bit values in the RDX:RAX register pair. Of course, the XMM/YMM registers are another good place to return large values. Just remember that these schemes are not Microsoft ABI–compliant, so they’re practical only when calling code you’ve written.
If you need to return a large object as a function result (say, an array of 1000 elements), you obviously are not going to be able to return the function result in the registers. You can deal with large function return results in two common ways: either pass the return value as a reference parameter or allocate storage on the heap (for example, using the C Standard Library malloc() function) for the object and return a pointer to it in a 64-bit register. Of course, if you return a pointer to storage you’ve allocated on the heap, the calling program must free this storage when it has finished with it.
5.9 Recursion
Recursion occurs when a procedure calls itself. The following, for example, is a recursive procedure:
Recursive proc
call Recursive
ret
Recursive endpOf course, the CPU will never return from this procedure. Upon entry into Recursive, this procedure will immediately call itself again, and control will never pass to the end of the procedure. In this particular case, runaway recursion results in an infinite loop.14
Like a looping structure, recursion requires a termination condition in order to stop infinite recursion. Recursive could be rewritten with a termination condition as follows:
Recursive proc
dec eax
jz allDone
call Recursive
allDone:
ret
Recursive endpThis modification to the routine causes Recursive to call itself the number of times appearing in the EAX register. On each call, Recursive decrements the EAX register by 1 and then calls itself again. Eventually, Recursive decrements EAX to 0 and returns from each call until it returns to the original caller.
So far, however, there hasn’t been a real need for recursion. After all, you could efficiently code this procedure as follows:
Recursive proc
iterLp:
dec eax
jnz iterLp
ret
Recursive endpBoth examples would repeat the body of the procedure the number of times passed in the EAX register.15 As it turns out, there are only a few recursive algorithms that you cannot implement in an iterative fashion. However, many recursively implemented algorithms are more efficient than their iterative counterparts, and most of the time the recursive form of the algorithm is much easier to understand.
The quicksort algorithm is probably the most famous algorithm that usually appears in recursive form. A MASM implementation of this algorithm appears in Listing 5-15.
; Listing 5-15
; Recursive quicksort.
option casemap:none
nl = 10
numElements = 10
.const
ttlStr byte "Listing 5-15", 0
fmtStr1 byte "Data before sorting: ", nl, 0
fmtStr2 byte "%d " ; Use nl and 0 from fmtStr3
fmtStr3 byte nl, 0
fmtStr4 byte "Data after sorting: ", nl, 0
.data
theArray dword 1,10,2,9,3,8,4,7,5,6
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; quicksort - Sorts an array using the
; quicksort algorithm.
; Here's the algorithm in C, so you can follow along:
void quicksort(int a[], int low, int high)
{
int i,j,Middle;
if(low < high)
{
Middle = a[(low+high)/2];
i = low;
j = high;
do
{
while(a[i] <= Middle) i++;
while(a[j] > Middle) j--;
if(i <= j)
{
swap(a[i],a[j]);
i++;
j--;
}
} while(i <= j);
// Recursively sort the two subarrays.
if(low < j) quicksort(a,low,j-1);
if(i < high) quicksort(a,j+1,high);
}
}
; Args:
; RCX (_a): Pointer to array to sort
; RDX (_lowBnd): Index to low bound of array to sort
; R8 (_highBnd): Index to high bound of array to sort
_a equ [rbp+16] ; Ptr to array
_lowBnd equ [rbp+24] ; Low bounds of array
_highBnd equ [rbp+32] ; High bounds of array
; Local variables (register save area):
saveR9 equ [rbp+40] ; Shadow storage for R9
saveRDI equ [rbp-8]
saveRSI equ [rbp-16]
saveRBX equ [rbp-24]
saveRAX equ [rbp-32]
; Within the procedure body, these registers
; have the following meaning:
; RCX: Pointer to base address of array to sort.
; EDX: Lower bound of array (32-bit index).
; R8D: Higher bound of array (32-bit index).
; EDI: index (i) into array.
; ESI: index (j) into array.
; R9D: Middle element to compare against.
quicksort proc
push rbp
mov rbp, rsp
sub rsp, 32
; This code doesn't mess with RCX. No
; need to save it. When it does mess
; with RDX and R8, it saves those registers
; at that point.
; Preserve other registers we use:
mov saveRAX, rax
mov saveRBX, rbx
mov saveRSI, rsi
mov saveRDI, rdi
mov saveR9, r9
mov edi, edx ; i = low
mov esi, r8d ; j = high
; Compute a pivotal element by selecting the
; physical middle element of the array.
lea rax, [rsi+rdi*1] ; RAX = i+j
shr rax, 1 ; (i + j)/2
mov r9d, [rcx][rax*4] ; Middle = ary[(i + j)/2]
; Repeat until the EDI and ESI indexes cross one
; another (EDI works from the start toward the end
; of the array, ESI works from the end toward the
; start of the array).
rptUntil:
; Scan from the start of the array forward
; looking for the first element greater or equal
; to the middle element):
dec edi ; To counteract inc, below
while1: inc edi ; i = i + 1
cmp r9d, [rcx][rdi*4] ; While Middle > ary[i]
jg while1
; Scan from the end of the array backward, looking
; for the first element that is less than or equal
; to the middle element.
inc esi ; To counteract dec, below
while2: dec esi ; j = j - 1
cmp r9d, [rcx][rsi*4] ; While Middle < ary[j]
jl while2
; If we've stopped before the two pointers have
; passed over one another, then we've got two
; elements that are out of order with respect
; to the middle element, so swap these two elements.
cmp edi, esi ; If i <= j
jnle endif1
mov eax, [rcx][rdi*4] ; Swap ary[i] and ary[j]
mov r9d, [rcx][rsi*4]
mov [rcx][rsi*4], eax
mov [rcx][rdi*4], r9d
inc edi ; i = i + 1
dec esi ; j = j - 1
endif1: cmp edi, esi ; Until i > j
jng rptUntil
; We have just placed all elements in the array in
; their correct positions with respect to the middle
; element of the array. So all elements at indexes
; greater than the middle element are also numerically
; greater than this element. Likewise, elements at
; indexes less than the middle (pivotal) element are
; now less than that element. Unfortunately, the
; two halves of the array on either side of the pivotal
; element are not yet sorted. Call quicksort recursively
; to sort these two halves if they have more than one
; element in them (if they have zero or one elements, then
; they are already sorted).
cmp edx, esi ; If lowBnd < j
jnl endif2
; Note: a is still in RCX,
; low is still in RDX.
; Need to preserve R8 (high).
; Note: quicksort doesn't require stack alignment.
push r8
mov r8d, esi
call quicksort ; (a, low, j)
pop r8
endif2: cmp edi, r8d ; If i < high
jnl endif3
; Note: a is still in RCX,
; High is still in R8D.
; Need to preserve RDX (low).
; Note: quicksort doesn't require stack alignment.
push rdx
mov edx, edi
call quicksort ; (a, i, high)
pop rdx
; Restore registers and leave:
endif3:
mov rax, saveRAX
mov rbx, saveRBX
mov rsi, saveRSI
mov rdi, saveRDI
mov r9, saveR9
leave
ret
quicksort endp
; Little utility to print the array elements:
printArray proc
push r15
push rbp
mov rbp, rsp
sub rsp, 40 ; Shadow parameters
lea r9, theArray
mov r15d, 0
whileLT10: cmp r15d, numElements
jnl endwhile1
lea rcx, fmtStr2
lea r9, theArray
mov edx, [r9][r15*4]
call printf
inc r15d
jmp whileLT10
endwhile1: lea rcx, fmtStr3
call printf
leave
pop r15
ret
printArray endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 32 ; Shadow storage
; Display unsorted array:
lea rcx, fmtStr1
call printf
call printArray
; Sort the array:
lea rcx, theArray
xor rdx, rdx ; low = 0
mov r8d, numElements-1 ; high = 9
call quicksort ; (theArray, 0, 9)
; Display sorted results:
lea rcx, fmtStr4
call printf
call printArray
leave
ret ; Returns to caller
asmMain endp
endListing 5-15: Recursive quicksort program
Here is the build command and sample output for the quicksort program:
C:\>build listing5-15
C:\>echo off
Assembling: listing5-15.asm
c.cpp
C:\>listing5-15
Calling Listing 5-15:
Data before sorting:
1
10
2
9
3
8
4
7
5
6
Data after sorting:
1
2
3
4
5
6
7
8
9
10
Listing 5-15 terminatedNote that this quicksort procedure uses registers for all local variables. The quicksort function is a leaf function; it doesn’t call any other functions. Therefore, it doesn’t need to align the stack on a 16-byte boundary. Also, as is a good idea for any pure-assembly procedure (that will be called only by other assembly language procedures), this quicksort procedure preserves all the registers whose values it modifies (even the volatile registers). That’s just good programming practice even if it is a little less efficient.
5.10 Procedure Pointers
The x86-64 call instruction allows three basic forms: PC-relative calls (via a procedure name), indirect calls through a 64-bit general-purpose register, and indirect calls through a quad-word pointer variable. The call instruction supports the following (low-level) syntax:
call proc_name ; Direct call to procedure proc_name
call reg64 ; Indirect call to procedure whose address
; appears in the reg64
call qwordVar ; Indirect call to the procedure whose address
; appears in the qwordVar quad-word variableWe’ve been using the first form throughout this book, so there is little need to discuss it here. The second form, the register indirect call, calls the procedure whose address is held in the specified 64-bit register. The address of a procedure is the byte address of the first instruction to execute within that procedure. On a von Neumann architecture machine (like the x86-64), the system stores machine instructions in memory along with other data. The CPU fetches the instruction opcode values from memory prior to executing them. When you execute the register indirect call instruction, the x86-64 first pushes the return address onto the stack and then begins fetching the next opcode byte (instruction) from the address specified by the register’s value.
The third form of the preceding call instruction fetches the address of a procedure’s first instruction from a quad-word variable in memory. Although this instruction suggests that the call uses the direct addressing of the procedure, you should realize that any legal memory addressing mode is also legal here. For example, call procPtrTable[rbx*8] is perfectly legitimate; this statement fetches the quad word from the array of quad words (procPtrTable) and calls the procedure whose address is the value contained within that quad word.
MASM treats procedure names like static objects. Therefore, you can compute the address of a procedure by using the offset operator along with the procedure’s name or by using the lea instruction. For example, offset proc_name is the address of the very first instruction of the proc_name procedure. So, all three of the following code sequences wind up calling the proc_name procedure:
call proc_name
.
.
.
mov rax, offset proc_name
call rax
.
.
.
lea rax, proc_name
call raxBecause the address of a procedure fits in a 64-bit object, you can store such an address into a quad-word variable; in fact, you can initialize a quad-word variable with the address of a procedure by using code like the following:
p proc
.
.
.
p endp
.
.
.
.data
ptrToP qword offset p
.
.
.
call ptrToP ; Calls p if ptrToP has not changedAs with all pointer objects, you should not attempt to indirectly call a procedure through a pointer variable unless you’ve initialized that variable with an appropriate address. You can initialize a procedure pointer variable in two ways: .data and .const objects allow an initializer, or you can compute the address of a routine (as a 64-bit value) and store that 64-bit address directly into the procedure pointer at runtime. The following code fragment demonstrates both ways to initialize a procedure pointer:
.data
ProcPointer qword offset p ; Initialize ProcPointer with
; the address of p
.
.
.
call ProcPointer ; First invocation calls p
; Reload ProcPointer with the address of q.
lea rax, q
mov ProcPointer, rax
.
.
.
call ProcPointer ; This invocation calls qAlthough all the examples in this section use static variable declarations (.data, .const, .data?), don’t think you can declare simple procedure pointers only in the static variable declaration sections. You can also declare procedure pointers (which are just qword variables) as local variables, pass them as parameters, or declare them as fields of a record or a union.
5.11 Procedural Parameters
One place where procedure pointers are quite invaluable is in parameter lists. Selecting one of several procedures to call by passing the address of a procedure is a common operation. Of course, a procedural parameter is just a quad-word parameter containing the address of a procedure, so this is really no different from using a local variable to hold a procedure pointer (except, of course, that the caller initializes the parameter with the address of the procedure to call indirectly).
When using parameter lists with the MASM proc directive, you can specify a procedure pointer type by using the proc type specifier; for example:
procWithProcParm proc parm1:word, procParm:procYou can call the procedure pointed at by this parameter by using the following call instruction:
call procParm5.12 Saving the State of the Machine, Part II
“Saving the State of the Machine” on page 220 described the use of the push and pop instructions to save the state of the registers across a procedure call (callee register preservation). While this is certainly one way to preserve registers across a procedure call, it certainly isn’t the only way, nor is it always (or even usually) the best way to save and restore registers.
The push and pop instructions have a couple of major benefits: they are short (pushing or popping a 64-bit register uses a 1-byte instruction opcode), and they work with constant and memory operands. These instructions do have drawbacks, however: they modify the stack pointer, they work with only 2- or 8-byte registers, they work only with the general-purpose integer registers (and the FLAGS register), and they might be slower than an equivalent instruction that moves the register data onto the stack. Often, a better solution is to reserve storage in the local variable space and simply move the registers to/from those local variables on the stack.
Consider the following procedure declaration that preserves registers by using push and pop instructions:
preserveRegs proc
push rax
push rbx
push rcx
.
.
.
pop rcx
pop rbx
pop rax
ret
preserveRegs endpYou can achieve the same thing with the following code:
preserveRegs proc
saveRAX textequ <[rsp+16]>
saveRBX textequ <[rsp+8]>
saveRCX textequ <[rsp]>
sub rsp, 24 ; Make room for locals
mov saveRAX, rax
mov saveRBX, rbx
mov saveRCX, rcx
.
.
.
mov rcx, saveRCX
mov rbx, saveRBX
mov rax, saveRAX
add rsp, 24 ; Deallocate locals
ret
preserveRegs endpThe disadvantage to this code is that two extra instructions are needed to allocate (and deallocate) storage on the stack for the local variables that hold the register values. The push and pop instructions automatically allocate this storage, sparing you from having to supply these extra instructions. For a simple situation such as this, the push and pop instructions probably are the better solution.
For more complex procedures, especially those that expect parameters on the stack or have local variables, the procedure is already setting up the activation record, and subtracting a larger number from RSP doesn’t require any additional instructions:
option prologue:PrologueDef
option epilogue:EpilogueDef
preserveRegs proc parm1:byte, parm2:dword
local localVar1:dword, localVar2:qword
local saveRAX:qword, saveRBX:qword
local saveRCX:qword
mov saveRAX, rax
mov saveRBX, rbx
mov saveRCX, rcx
.
.
.
mov rcx, saveRCX
mov rbx, saveRBX
mov rax, saveRAX
ret
preserveRegs endpMASM automatically generates the code to allocate the storage for saveRAX, saveRBX, and saveRCX (along with all the other local variables) on the stack, as well as clean up the local storage on return.
When allocating local variables on the stack along with storage for any parameters a procedure might pass to functions it calls, pushing and popping registers to preserve them becomes problematic. For example, consider the following procedure:
callsFuncs proc
saveRAX textequ <[rbp-8]>
saveRBX textequ <[rbp-16]>
saveRCX textequ <[rbp-24]>
push rbp
mov rbp, rsp
sub rsp, 48 ; Make room for locals and parms
mov saveRAX, rax ; Preserve registers in
mov saveRBX, rbx ; local variables
mov saveRCX, rcx
.
.
.
mov [rsp], rax ; Store parm1
mov [rsp+8], rbx ; Store parm2
mov [rsp+16], rcx ; Store parm3
call theFunction
.
.
.
mov rcx, saveRCX ; Restore registers
mov rbx, saveRBX
mov rax, saveRAX
leave ; Deallocate locals
ret
callsFuncs endpHad this function pushed RAX, RBX, and RCX on the stack after subtracting 48 from RSP, those save registers would have wound up on the stack where the function passes parm1, parm2, and parm3 to theFunction. That’s why the push and pop instructions don’t work well when working with functions that build an activation record containing local storage.
5.13 Microsoft ABI Notes
This chapter has all but completed the discussion of the Microsoft calling conventions. Specifically, a Microsoft ABI–compliant function must follow these rules:
- (Scalar) parameters must be passed in RCX, RDX, R8, and R9, then pushed on the stack. Floating-point parameters substitute XMM0, XMM1, XMM2, and XMM3 for RCX, RDX, R8, and R9, respectively.
- Varargs functions (functions with a variable number of parameters, such as
printf()) and unprototyped functions must pass floating-point values in both the general-purpose (integer) registers and in the XMM registers. (For what it’s worth,printf()seems to be happy with just passing the floating-point values in the integer registers, though that might be a happy accident with the version of MSVC used in the preparation of this book.) - All parameters must be less than or equal to 64 bits in size; larger parameters must be passed by reference.
- On the stack, parameters always consume 64 bits (8 bytes) regardless of their actual size; the HO bits of smaller objects are undefined.
- Immediately before a
callinstruction, the stack must be aligned on a 16-byte boundary. - Registers RAX, RCX, RDX, R8, R9, R10, R11, and XMM0/YMM0 to XMM5/YMM5 are volatile. The caller must preserve the registers across a call if it needs their values to be saved across the call. Also note that the HO 128 bits of YMM0 to YMM15 are volatile, and the caller must preserve these registers if it needs these bits to be preserved across a call.
- Registers RBX, RSI, RDI, RBP, RSP, R12 to R15, and XMM6 to XMM15 are nonvolatile. The callee must preserve these registers if it changes their values. As noted earlier, while YMM0L to YMM15L (the LO 128 bits) are nonvolatile, the upper 128 bits of these registers can be considered volatile. However, if a procedure is saving the LO 128 bits of YMM0 to YMM15, it may as well preserve all the bits (this inconsistency in the Microsoft ABI is to support legacy code running on CPUs that don’t support the YMM registers).
- Scalar function returns (64 bits or fewer) come back in the RAX register. If the data type is smaller than 64 bits, the HO bits of RAX are undefined.
- Functions that return values larger than 64 bits must allocate storage for the return value and pass the address of that storage in the first parameter (RCX) to the function. On return, the function must return this pointer in the RAX register.
- Functions return floating-point results (double or single) in the XMM0 register.
5.14 For More Information
The electronic edition of the 32-bit edition this book (found at https://artofasm.randallhyde.com/) contains a whole “volume” on advanced and intermediate procedures. Though that book covers 32-bit assembly language programming, the concepts apply directly to 64-bit assembly by simply using 64-bit addresses rather than 32-bit addresses.
While the information appearing in this chapter covers 99 percent of the material that assembly programmers typically use, there is additional information on procedures and parameters that you may find interesting. In particular, the electronic edition covers additional parameter-passing mechanisms (pass by value/result, pass by result, pass by name, and pass by lazy evaluation) and goes into greater detail about the places you can pass parameters. The electronic version also covers iterators, thunks, and other advanced procedure types. Finally, a good compiler construction textbook will cover additional details about runtime support for procedures.
For more information on the Microsoft ABI, search for Microsoft calling conventions on the Microsoft website (or on the internet).
5.15 Test Yourself
- Explain, step by step, how the
callinstruction works. - Explain, step by step, how the
retinstruction works. - What does the
retinstruction, with a numeric constant operand, do? - What value is pushed on the stack for a return address?
- What is namespace pollution?
- How do you define a single global symbol in a procedure?
- How would you make all symbols in a procedure non-scoped (that is, all the symbols in a procedure would be global)?
- Explain how to use the
pushandpopinstructions to preserve registers in a function. - What is the main disadvantage of caller preservation?
- What is the main problem with callee preservation?
- What happens if you fail to pop a value in a function that you pushed on the stack at the beginning of the function?
- What happens if you pop extra data off the stack in a function (data that you did not push on the stack in the function)?
- What is an activation record?
- What register usually points at an activation record, providing access to the data in that record?
- How many bytes are reserved for a typical parameter on the stack when using the Microsoft ABI?
- What is the standard entry sequence for a procedure (the instructions)?
- What is the standard exit sequence for a procedure (the instructions)?
- What instruction can you use to force 16-byte alignment of the stack pointer if the current value in RSP is unknown?
- What is the scope of a variable?
- What is the lifetime of a variable?
- What is an automatic variable?
- When does the system allocate storage for an automatic variable?
- Explain two ways to declare local/automatic variables in a procedure.
- Given the following procedure source code snippet, provide the offsets for each of the local variables:
procWithLocals proc local var1:word, local2:dword, dVar:byte local qArray[2]:qword, rlocal[2]:real4 local ptrVar:qword . . ; Other statements in the procedure. . procWithLocals endp - What statement(s) would you insert in the source file to tell MASM to automatically generate the standard entry and standard exit sequences for a procedure?
- When MASM automatically generates a standard entry sequence for a procedure, how does it determine where to put the code sequence?
- When MASM automatically generates a standard exit sequence for a procedure, how does it determine where to put the code sequence?
- What value does a pass-by-value parameter pass to a function?
- What value does a pass-by-reference parameter pass to a function?
- When passing four integer parameters to a function, where does the Windows ABI state those parameters are to be passed?
- When passing a floating-point value as one of the first four parameters, where does the Windows ABI insist the values will be passed?
- When passing more than four parameters to a function, where does the Windows ABI state the parameters will be passed?
- What is the difference between a volatile and nonvolatile register in the Windows ABI?
- Which registers are volatile in the Windows ABI?
- Which registers are nonvolatile in the Windows ABI?
- When passing parameters in the code stream, how does a function access the parameter data?
- What is a shadow parameter?
- How many bytes of shadow storage will a function require if it has a single 32-bit integer parameter?
- How many bytes of shadow storage will a function require if it has two 64-bit integer parameters?
- How many bytes of shadow storage will a function require if it has six 64-bit integer parameters?
- What offsets will MASM associate with each of the parameters in the following
procdeclaration?procWithParms proc parm1:byte, parm2:word, parm3:dword, parm4:qword - Suppose that
parm4in the preceding question is a pass-by-reference character parameter. How would you load that character into the AL register (provide a code sequence)? - What offsets will MASM associate with each of the local variables in the following
procsnippet?procWithLocals proc local lclVar1:byte, lclVar2:word, lclVar3:dword, lclVar4:qword - What is the best way to pass a large array to a procedure?
- What does ABI stand for?
- Where is the most common place to return a function result?
- What is a procedural parameter?
- How would you call a procedure passed as a parameter to a function/procedure?
- If a procedure has local variables, what is the best way to preserve registers within that procedure?