7
Low-Level Control Structures

This chapter discusses how to convert high-level–language control structures into assembly language control statements. The examples up to this point have created assembly control structures in an ad hoc manner. Now it’s time to formalize how to control the operation of your assembly language programs. By the time you finish this chapter, you should be able to convert HLL control structures into assembly language.
Control structures in assembly language consist of conditional branches and indirect jumps. This chapter discusses those instructions and how to emulate HLL control structures (such as if/else, switch, and loop statements). This chapter also discusses labels (the targets of conditional branches and jump statements) as well as the scope of labels in an assembly language source file.
7.1 Statement Labels
Before discussing jump instructions and how to emulate control structures using them, an in-depth discussion of assembly language statement labels is necessary. In an assembly language program, labels stand in as symbolic names for addresses. It is far more convenient to refer to a position in your code by using a name such as LoopEntry rather than a numeric address such as 0AF1C002345B7901Eh. For this reason, assembly language low-level control structures make extensive use of labels within source code (see “Brief Detour: An Introduction to Control Transfer Instructions” in Chapter 2).
You can do three things with (code) labels: transfer control to a label via a (conditional or unconditional) jump instruction, call a label via the call instruction, and take the address of a label. Taking the address of a label is useful when you want to indirectly transfer control to that address at a later point in your program.
The following code sequence demonstrates two ways to take the address of a label in your program (using the lea instruction and using the offset operator):
stmtLbl:
.
.
.
mov rcx, offset stmtLbl2
.
.
.
lea rax, stmtLbl
.
.
.
stmtLbl2:Because addresses are 64-bit quantities, you’ll typically load an address into a 64-bit general-purpose register by using the lea instruction. Because that instruction uses a 32-bit relative displacement from the current instruction, the instruction encoding is significantly shorter than the mov instruction (which encodes a full 8-byte constant in addition to the opcode bytes).
7.1.1 Using Local Symbols in Procedures
Statement labels you define within a proc/endp procedure are local to that procedure, in the sense of lexical scope: the statement label is visible only within that procedure; you cannot refer to that statement label outside the procedure. Listing 7-1 demonstrates that you cannot refer to a symbol inside another procedure (note that this program will not assemble because of this error).
; Listing 7-1
; Demonstration of local symbols.
; Note that this program will not
; compile; it fails with an
; undefined symbol error.
option casemap:none
.code
hasLocalLbl proc
localStmLbl:
ret
hasLocalLbl endp
; Here is the "asmMain" function.
asmMain proc
asmLocal: jmp asmLocal ; This is okay
jmp localStmtLbl ; Undefined in asmMain
asmMain endp
endListing 7-1: Demonstration of lexically scoped symbols
The command to assemble this file (and the corresponding diagnostic message) is as follows:
C:\>ml64 /c listing7-1.asm
Microsoft (R) Macro Assembler (x64) Version 14.15.26730.0
Copyright (C) Microsoft Corporation. All rights reserved.
Assembling: listing7-1.asm
listing7-1.asm(26) : error A2006:undefined symbol : localStmtLblIf you really want to access a statement (or any other) label outside a procedure, you can use the option directive to turn off local scope within a section of your program, as noted in Chapter 5:
option noscoped
option scopedThe first form tells MASM to stop making symbols (inside proc/endp) local to the procedure containing them. The second form restores the lexical scoping of symbols in procedures. Therefore, using these two directives, you can turn scoping on or off for various sections of your source file (including as little as a single statement, if you like). Listing 7-2 demonstrates how to use the option directive to make a single symbol global outside the procedure containing it (note that this program still has compile errors).
; Listing 7-2
; Demonstration of local symbols #2.
; Note that this program will not
; compile; it fails with two
; undefined symbol errors.
option casemap:none
.code
hasLocalLbl proc
localStmLbl:
option noscoped
notLocal:
option scoped
isLocal:
ret
hasLocalLbl endp
; Here is the "asmMain" function.
asmMain proc
lea rcx, localStmtLbl ; Generates an error
lea rcx, notLocal ; Assembles fine
lea rcx, isLocal ; Generates an error
asmMain endp
endListing 7-2: The option scoped and option noscoped directives
Here’s the build command (and diagnostic output) for Listing 7-2:
C:\>ml64 /c listing7-2.asm
Microsoft (R) Macro Assembler (x64) Version 14.15.26730.0
Copyright (C) Microsoft Corporation. All rights reserved.
Assembling: listing7-2.asm
listing7-2.asm(29) : error A2006:undefined symbol : localStmtLbl
listing7-2.asm(31) : error A2006:undefined symbol : isLocalAs you can see from MASM’s output, the notLocal symbol (appearing after the option noscoped directive) did not generate an undefined symbol error. However, the localStmtLbl and isLocal symbols, which are local to hasLocalLbl, are undefined outside that procedure.
7.1.2 Initializing Arrays with Label Addresses
MASM also allows you to initialize quad-word variables with the addresses of statement labels. However, labels that appear in the initialization portions of variable declarations have some restrictions. The most important restriction is that the symbol must be in the same lexical scope as the data declaration attempting to use it. So, either the qword directive must appear inside the same procedure as the statement label, or you must use the option noscoped directive to make the symbol(s) global to the procedure. Listing 7-3 demonstrates these two ways to initialize a qword variable with statement label addresses.
; Listing 7-3
; Initializing qword values with the
; addresses of statement labels.
option casemap:none
.data
lblsInProc qword globalLbl1, globalLbl2 ; From procWLabels
.code
; procWLabels - Just a procedure containing private (lexically scoped)
; and global symbols. This really isn't an executable
; procedure.
procWLabels proc
privateLbl:
nop ; "No operation" just to consume space
option noscoped
globalLbl1: jmp globalLbl2
globalLbl2: nop
option scoped
privateLbl2:
ret
dataInCode qword privateLbl, globalLbl1
qword globalLbl2, privateLbl2
procWLabels endp
endListing 7-3: Initializing qword variables with the address of statement labels
If you compile Listing 7-3 with the following command, you’ll get no assembly errors:
ml64 /c /Fl listing7-3.asmIf you look at the listing7-3.lst output file that MASM produces, you can see that MASM properly initializes the qword declarations with the (section-relative/relocatable) offsets of the statement labels:
00000000 .data
00000000 lblsInProc qword globalLbl1, globalLbl2
0000000000000001 R
0000000000000003 R
.
.
.
00000005 dataInCode qword privateLbl, globalLbl1
0000000000000000 R
0000000000000001 R
00000015 0000000000000003 R qword globalLbl2, privateLbl2
0000000000000004 RTransferring control to a statement label inside a procedure is generally considered bad programming practice. Unless you have a good reason to do so, you probably shouldn’t.
As addresses on the x86-64 are 64-bit quantities, you will typically use the qword directive (as in the previous examples) to initialize a data object with the address of a statement label. However, if your program is (always going to be) smaller than 2GB, and you set the LARGEADDRESSAWARE:NO flag (using sbuild.bat), you can get away with using dword data declarations to hold the address of a label. Of course, as this book has pointed out many times, using 32-bit addresses in your 64-bit programs can lead to problems if you ever exceed 2GB of storage for your program.
7.2 Unconditional Transfer of Control (jmp)
The jmp (jump) instruction unconditionally transfers control to another point in the program. This instruction has three forms: a direct jump and two indirect jumps. These take the following forms:
jmp label
jmp reg64
jmp mem64 The first instruction is a direct jump, which you’ve seen in various sample programs up to this point. For direct jumps, you normally specify the target address by using a statement label. The label appears either on the same line as an executable machine instruction or by itself on a line preceding an executable machine instruction. The direct jump is completely equivalent to a goto statement in a high-level language.1
Here’s an example:
Statements
jmp laterInPgm
.
.
.
laterInPgm:
Statements7.2.1 Register-Indirect Jumps
The second form of the jmp instruction given earlier—jmp reg64—is a register-indirect jump instruction that transfers control to the instruction whose address appears in the specified 64-bit general-purpose register. To use this form of the jmp instruction, you must load a 64-bit register with the address of a machine instruction prior to the execution of the jmp. When several paths, each loading the register with a different address, converge on the same jmp instruction, control transfers to an appropriate location determined by the path up to that point.
Listing 7-4 reads a string of characters from the user that contain an integer value. It uses the C Standard Library function strtol() to convert that string to a binary integer value. The strtol() function doesn’t do the greatest job of reporting an error, so this program tests the return results to verify a correct input and uses register-indirect jumps to transfer control to different code paths based on the result.
The first part of Listing 7-4 contains constants, variables, external declarations, and the (usual) getTitle() function.
; Listing 7-4
; Demonstration of register-indirect jumps.
option casemap:none
nl = 10
maxLen = 256
EINVAL = 22 ; "Magic" C stdlib constant, invalid argument
ERANGE = 34 ; Value out of range
.const
ttlStr byte "Listing 7-4", 0
fmtStr1 byte "Enter an integer value between "
byte "1 and 10 (0 to quit): ", 0
badInpStr byte "There was an error in readLine "
byte "(ctrl-Z pressed?)", nl, 0
invalidStr byte "The input string was not a proper number"
byte nl, 0
rangeStr byte "The input value was outside the "
byte "range 1-10", nl, 0
unknownStr byte "There was a problem with strToInt "
byte "(unknown error)", nl, 0
goodStr byte "The input value was %d", nl, 0
fmtStr byte "result:%d, errno:%d", nl, 0
.data
externdef _errno:dword ; Error return by C code
endStr qword ?
inputValue dword ?
buffer byte maxLen dup (?)
.code
externdef readLine:proc
externdef strtol:proc
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endpThe next section of Listing 7-4 is the strToInt() function, a wrapper around the C Standard Library strtol() function that does a more thorough job of handling erroneous inputs from the user. See the comments for the function’s return values.
; strToInt - Converts a string to an integer, checking for errors.
; Argument:
; RCX - Pointer to string containing (only) decimal
; digits to convert to an integer.
; Returns:
; RAX - Integer value if conversion was successful.
; RCX - Conversion state. One of the following:
; 0 - Conversion successful.
; 1 - Illegal characters at the beginning of the
; string (or empty string).
; 2 - Illegal characters at the end of the string.
; 3 - Value too large for 32-bit signed integer.
strToInt proc
strToConv equ [rbp+16] ; Flush RCX here
endPtr equ [rbp-8] ; Save ptr to end of str
push rbp
mov rbp, rsp
sub rsp, 32h ; Shadow + 16-byte alignment
mov strToConv, rcx ; Save, so we can test later
; RCX already contains string parameter for strtol:
lea rdx, endPtr ; Ptr to end of string goes here
mov r8d, 10 ; Decimal conversion
call strtol
; On return:
; RAX - Contains converted value, if successful.
; endPtr - Pointer to 1 position beyond last char in string.
; If strtol returns with endPtr == strToConv, then there were no
; legal digits at the beginning of the string.
mov ecx, 1 ; Assume bad conversion
mov rdx, endPtr
cmp rdx, strToConv
je returnValue
; If endPtr is not pointing at a zero byte, then we've got
; junk at the end of the string.
mov ecx, 2 ; Assume junk at end
mov rdx, endPtr
cmp byte ptr [rdx], 0
jne returnValue
; If the return result is 7FFF_FFFFh or 8000_0000h (max long and
; min long, respectively), and the C global _errno variable
; contains ERANGE, then we've got a range error.
mov ecx, 0 ; Assume good input
cmp _errno, ERANGE
jne returnValue
mov ecx, 3 ; Assume out of range
cmp eax, 7fffffffh
je returnValue
cmp eax, 80000000h
je returnValue
; If we get to this point, it's a good number.
mov ecx, 0
returnValue:
leave
ret
strToInt endpThe final section of Listing 7-4 is the main program. This is the part of code most interesting to us. It loads the RBX register with the address of code to execute based on the strToInt() return results. The strToInt() function returns one of the following states (see the comments in the previous code for an explanation):
- Valid input
- Illegal characters at the beginning of the string
- Illegal characters at the end of the string
- Range error
The program then transfers control to different sections of asmMain() based on the value held in RBX (which specifies the type of result strToInt() returns).
; Here is the "asmMain" function.
public asmMain
asmMain proc
saveRBX equ qword ptr [rbp-8] ; Must preserve RBX
push rbp
mov rbp, rsp
sub rsp, 48 ; Shadow storage
mov saveRBX, rbx ; Must preserve RBX
; Prompt the user to enter a value
; between 1 and 10:
repeatPgm: lea rcx, fmtStr1
call printf
; Get user input:
lea rcx, buffer
mov edx, maxLen ; Zero-extends!
call readLine
lea rbx, badInput ; Initialize state machine
test rax, rax ; RAX is -1 on bad input
js hadError ; (only neg value readLine returns)
; Call strToInt to convert string to an integer and
; check for errors:
lea rcx, buffer ; Ptr to string to convert
call strToInt
lea rbx, invalid
cmp ecx, 1
je hadError
cmp ecx, 2
je hadError
lea rbx, range
cmp ecx, 3
je hadError
lea rbx, unknown
cmp ecx, 0
jne hadError
; At this point, input is valid and is sitting in EAX.
; First, check to see if the user entered 0 (to quit
; the program).
test eax, eax ; Test for zero
je allDone
; However, we need to verify that the number is in the
; range 1-10.
lea rbx, range
cmp eax, 1
jl hadError
cmp eax, 10
jg hadError
; Pretend a bunch of work happens here dealing with the
; input number.
lea rbx, goodInput
mov inputValue, eax
; The different code streams all merge together here to
; execute some common code (we'll pretend that happens;
; for brevity, no such code exists here).
hadError:
; At the end of the common code (which doesn't mess with
; RBX), separate into five different code streams based
; on the pointer value in RBX:
jmp rbx
; Transfer here if readLine returned an error:
badInput: lea rcx, badInpStr
call printf
jmp repeatPgm
; Transfer here if there was a non-digit character
; in the string:
invalid: lea rcx, invalidStr
call printf
jmp repeatPgm
; Transfer here if the input value was out of range:
range: lea rcx, rangeStr
call printf
jmp repeatPgm
; Shouldn't ever get here. Happens if strToInt returns
; a value outside the range 0-3.
unknown: lea rcx, unknownStr
call printf
jmp repeatPgm
; Transfer down here on a good user input.
goodInput: lea rcx, goodStr
mov edx, inputValue ; Zero-extends!
call printf
jmp repeatPgm
; Branch here when the user selects "quit program" by
; entering the value zero:
allDone: mov rbx, saveRBX ; Must restore before returning
leave
ret ; Returns to caller
asmMain endp
endListing 7-4: Using register-indirect jmp instructions
Here’s the build command and a sample run of the program in Listing 7-4:
C:\>build listing7-4
C:\>echo off
Assembling: listing7-4.asm
c.cpp
C:\>listing7-4
Calling Listing 7-4:
Enter an integer value between 1 and 10 (0 to quit): ^Z
There was an error in readLine (ctrl-Z pressed?)
Enter an integer value between 1 and 10 (0 to quit): a123
The input string was not a proper number
Enter an integer value between 1 and 10 (0 to quit): 123a
The input string was not a proper number
Enter an integer value between 1 and 10 (0 to quit): 1234567890123
The input value was outside the range 1-10
Enter an integer value between 1 and 10 (0 to quit): -1
The input value was outside the range 1-10
Enter an integer value between 1 and 10 (0 to quit): 11
The input value was outside the range 1-10
Enter an integer value between 1 and 10 (0 to quit): 5
The input value was 5
Enter an integer value between 1 and 10 (0 to quit): 0
Listing 7-4 terminated7.2.2 Memory-Indirect Jumps
The third form of the jmp instruction is a memory-indirect jump, which fetches the quad-word value from the memory location and jumps to that address. This is similar to the register-indirect jmp except the address appears in a memory location rather than in a register.
Listing 7-5 demonstrates a rather trivial use of this form of the jmp instruction.
; Listing 7-5
; Demonstration of memory-indirect jumps.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 7-5", 0
fmtStr1 byte "Before indirect jump", nl, 0
fmtStr2 byte "After indirect jump", nl, 0
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 48 ; Shadow storage
lea rcx, fmtStr1
call printf
jmp memPtr
memPtr qword ExitPoint
ExitPoint: lea rcx, fmtStr2
call printf
leave
ret ; Returns to caller
asmMain endp
endListing 7-5: Using memory-indirect jmp instructions
Here’s the build command and output for Listing 7-5:
C:\>build listing7-5
C:\>echo off
Assembling: listing7-5.asm
c.cpp
C:\>listing7-5
Calling Listing 7-5:
Before indirect jump
After indirect jump
Listing 7-5 terminatedNote that you can easily crash your system if you execute an indirect jump with an invalid pointer value.
7.3 Conditional Jump Instructions
Although Chapter 2 provided an overview of the conditional jump instructions, repeating that discussion and expanding upon it here is worthwhile as conditional jumps are the principal tool for creating control structures in assembly language.
Unlike the unconditional jmp instruction, the conditional jump instructions do not provide an indirect form. They only allow a branch to a statement label in your program.
Intel’s documentation defines various synonyms or instruction aliases for many conditional jump instructions. Tables 7-1, 7-2, and 7-3 list all the aliases for a particular instruction, as well as the opposite branches. You’ll soon see the purpose of the opposite branches.
Table 7-1: jcc Instructions That Test Flags
| Instruction | Description | Condition | Aliases | Opposite |
jc |
Jump if carry | Carry = 1 | jb, jnae |
jnc |
jnc |
Jump if no carry | Carry = 0 | jnb, jae |
jc |
jz |
Jump if zero | Zero = 1 | je |
jnz |
jnz |
Jump if not zero | Zero = 0 | jne |
jz |
js |
Jump if sign | Sign = 1 | jns |
|
jns |
Jump if no sign | Sign = 0 | js |
|
jo |
Jump if overflow | Overflow = 1 | jno |
|
jno |
Jump if no overflow | Overflow = 0 | jo |
|
jp |
Jump if parity | Parity = 1 | jpe |
jnp |
jpe |
Jump if parity even | Parity = 1 | jp |
jpo |
jnp |
Jump if no parity | Parity = 0 | jpo |
jp |
jpo |
Jump if parity odd | Parity = 0 | jnp |
jpe |
Table 7-2: jcc Instructions for Unsigned Comparisons
| Instruction | Description | Condition | Aliases | Opposite |
ja |
Jump if above (>) |
Carry = 0, Zero = 0 | jnbe |
jna |
jnbe |
Jump if not below or equal (not ≤) |
Carry = 0, Zero = 0 | ja |
jbe |
jae |
Jump if above or equal (≥) |
Carry = 0 | jnc, jnb |
jnae |
jnb |
Jump if not below (not <) |
Carry = 0 | jnc, jae |
jb |
jb |
Jump if below (<) |
Carry = 1 | jc, jnae |
jnb |
jnae |
Jump if not above or equal (not ≥) |
Carry = 1 | jc, jb |
jae |
jbe |
Jump if below or equal (≤) |
Carry = 1 or Zero = 1 | jna |
jnbe |
jna |
Jump if not above (not >) |
Carry = 1 or Zero = 1 | jbe |
ja |
je |
Jump if equal (=) |
Zero = 1 | jz |
jne |
jne |
Jump if not equal (≠) |
Zero = 0 | jnz |
je |
Table 7-3: jcc Instructions for Signed Comparisons
| Instruction | Description | Condition | Aliases | Opposite |
jg |
Jump if greater (>) |
Sign = Overflow or Zero = 0 | jnle |
jng |
jnle |
Jump if not less than or equal (not ≤) |
Sign = Overflow or Zero = 0 | jg |
jle |
jge |
Jump if greater than or equal (≥) |
Sign = Overflow | jnl |
jnge |
jnl |
Jump if not less than (not <) |
Sign = Overflow | jge |
jl |
jl |
Jump if less than (<) |
Sign ≠ Overflow |
jnge |
jnl |
jnge |
Jump if not greater or equal (not ≥) |
Sign ≠ Overflow |
jl |
jge |
jle |
Jump if less than or equal (≤) |
Sign ≠ Oveflow or Zero = 1 |
jng |
jnle |
jng |
Jump if not greater than (not >) |
Sign ≠ Overflow or Zero = 1 |
jle |
jg |
je |
Jump if equal (=) |
Zero = 1 | jz |
jne |
jne |
Jump if not equal (≠) |
Zero = 0 | jnz |
je |
In many instances, you will need to generate the opposite of a specific branch instruction (examples appear later in this section). With only two exceptions, the opposite branch (N/No N) rule describes how to generate an opposite branch:
- If the second letter of the
jcc instruction is not ann, insert annafter thej. For example,jebecomesjne, andjlbecomesjnl. - If the second letter of the
jcc instruction is ann, remove thatnfrom the instruction. For example,jngbecomesjg, andjnebecomesje.
The two exceptions to this rule are jpe (jump if parity is even) and jpo (jump if parity is odd).2 However, you can use the aliases jp and jnp as synonyms for jpe and jpo, and the N/No N rule applies to jp and jnp.
The x86-64 conditional jump instructions give you the ability to split program flow into one of two paths depending on a certain condition. Suppose you want to increment the AX register if BX is equal to CX. You can accomplish this with the following code:
cmp bx, cx
jne SkipStmts;
inc ax
SkipStmts:Instead of checking for equality directly and branching to code to handle that condition, the common approach is to use the opposite branch to skip over the instructions you want to execute if the condition is true. That is, if BX is not equal to CX, jump over the increment instruction. Always use the opposite branch (N/No N) rule given earlier to select the opposite branch.
You can also use the conditional jump instructions to synthesize loops. For example, the following code sequence reads a sequence of characters from the user and stores each character in successive elements of an array until the user presses enter (newline):
mov edi, 0
RdLnLoop:
call getchar ; Some function that reads a character
; into the AL register
mov Input[rdi], al ; Store away the character
inc rdi ; Move on to the next character
cmp al, nl ; See if the user pressed ENTER
jne RdLnLoopThe conditional jump instructions only test the x86-64 flags; they do not affect any of them.
From an efficiency point of view, it’s important to note that each conditional jump has two machine code encodings: a 2-byte form and a 6-byte form.
The 2-byte form consists of the jcc opcode followed by a 1-byte PC-relative displacement. The 1-byte displacement allows the instruction to transfer control to a target instruction within about ±127 bytes around the current instruction. Given that the average x86-64 instruction is probably 4 to 5 bytes long, the 2-byte form of jcc is capable of branching to a target instruction within about 20 to 25 instructions.
Because a range of 20 to 25 instructions is insufficient for all conditional jumps, the x86-64 provides a second (6-byte) form with a 2-byte opcode and a 4-byte displacement. The 6-byte form gives you the ability to jump to an instruction within approximately ±2GB of the current instruction, which is probably sufficient for any reasonable program out there.
If you have the opportunity to branch to a nearby label rather than one that is far away (and still achieve the same result), branching to the nearby label will make your code shorter and possibly faster.
7.4 Trampolines
In the rare case you need to branch to a location beyond the range of the 6-byte jcc instructions, you can use an instruction sequence such as the following:
jncc skipJmp ; Opposite jump of the one you want to use
jmp destPtr ; JMP PC-relative is also limited to ±2GB
destPtr qword destLbl ; so code must use indirect jump
skipJmp:The opposite conditional branch transfers control to the normal fall-though point in the code (the code you’d normally fall through to if the condition is false). If the condition is true, control transfers to a memory-indirect jump that jumps to the original target location via a 64-bit pointer.
This sequence is known as a trampoline, because a program jumps to this point to jump even further in the program (much like how jumping on a trampoline lets you jump higher and higher). Trampolines are useful for call and unconditional jump instructions that use the PC-relative addressing mode (and, thus, are limited to a ±2GB range around the current instruction).
You’ll rarely use trampolines to transfer to another location within your program. However, trampolines are useful when transferring control to a dynamically linked library or OS subroutine that could be far away in memory.
7.5 Conditional Move Instructions
Sometimes all you need to do after a comparison or other conditional test is to load a value into a register (and, conversely, not load that value if the test or comparison fails). Because branches can be somewhat expensive to execute, the x86-64 CPUs support a set of conditional move instructions, cmovcc. These instructions appear in Tables 7-4, 7-5, and 7-6; the generic syntax for these instructions is as follows:
cmovcc reg16, reg16
cmovcc reg16, mem16
cmovcc reg32, reg32
cmovcc reg32, mem32
cmovcc reg64, reg64
cmovcc reg64, mem64The destination is always a general-purpose register (16, 32, or 64 bits). You can use these instructions only to load a register from memory or copy data from one register to another; you cannot use them to conditionally store data to memory.
Table 7-4: cmovcc Instructions That Test Flags
| Instruction | Description | Condition | Aliases |
cmovc |
Move if carry | Carry = 1 | cmovb, cmovnae |
cmovnc |
Move if no carry | Carry = 0 | cmovnb, cmovae |
cmovz |
Move if zero | Zero = 1 | cmove |
cmovnz |
Move if not zero | Zero = 0 | cmovne |
cmovs |
Move if sign | Sign = 1 | |
cmovns |
Move if no sign | Sign = 0 | |
cmovo |
Move if overflow | Overflow = 1 | |
cmovno |
Move if no overflow | Overflow = 0 | |
cmovp |
Move if parity | Parity = 1 | cmovpe |
cmovpe |
Move if parity even | Parity = 1 | cmovp |
cmovnp |
Move if no parity | Parity = 0 | cmovpo |
cmovpo |
Move if parity odd | Parity = 0 | cmovnp |
Table 7-5: cmovcc Instructions for Unsigned Comparisons
| Instruction | Description | Condition | Aliases |
cmova |
Move if above (>) |
Carry = 0, Zero = 0 | cmovnbe |
cmovnbe |
Move if not below or equal (not ≤) |
Carry = 0, Zero = 0 | cmova |
cmovae |
Move if above or equal (≥) |
Carry = 0 | cmovnc, cmovnb |
cmovnb |
Move if not below (not <) |
Carry = 0 | cmovnc, cmovae |
cmovb |
Move if below (<) |
Carry = 1 | cmovc, cmovnae |
cmovnae |
Move if not above or equal (not ≥) |
Carry = 1 | cmovc, cmovb |
cmovbe |
Move if below or equal (≤) |
Carry = 1 or Zero = 1 | cmovna |
cmovna |
Move if not above (not >) |
Carry = 1 or Zero = 1 | cmovbe |
cmove |
Move if equal (=) |
Zero = 1 | cmovz |
cmovne |
Move if not equal (≠) |
Zero = 0 | cmovnz |
Table 7-6: cmovcc Instructions for Signed Comparisons
| Instruction | Description | Condition | Aliases |
cmovg |
Move if greater (>) |
Sign = Overflow or Zero = 0 | cmovnle |
cmovnle |
Move if not less than or equal (not ≤) |
Sign = Overflow or Zero = 0 | cmovg |
cmovge |
Move if greater than or equal (≥) |
Sign = Overflow | cmovnl |
cmovnl |
Move if not less than (not <) |
Sign = Overflow | cmovge |
cmovl |
Move if less than (<) |
Sign != Overflow | cmovnge |
cmovnge |
Move if not greater or equal (not ≥) |
Sign != Overflow | cmovl |
cmovle |
Move if less than or equal (≤) |
Sign != Overflow or Zero = 1 | cmovng |
cmovng |
Move if not greater than (not >) |
Sign != Overflow or Zero = 1 | cmovle |
cmove |
Move if equal (=) |
Zero = 1 | cmovz |
cmovne |
Move if not equal (≠) |
Zero = 0 | cmovnz |
In addition, a set of conditional floating-point move instructions (fcmovcc) will move data between ST0 and one of the other FPU registers on the FPU stack. Sadly, these instructions aren’t all that useful in modern programs. See the Intel documentation for more details if you’re interested in using them.
7.6 Implementing Common Control Structures in Assembly Language
This section shows you how to implement decisions, loops, and other control constructs using pure assembly language.
7.6.1 Decisions
In its most basic form, a decision is a branch within the code that switches between two possible execution paths based on a certain condition. Normally (though not always), conditional instruction sequences are implemented with the conditional jump instructions. Conditional instructions correspond to the if/then/endif statement in an HLL:
if(expression) then
Statements
endif;To convert this to assembly language, you must write statements that evaluate the expression and then branch around the statements if the result is false. For example, if you had the C statements
if(a == b)
{
printf("a is equal to b \ n");
} you could translate this to assembly as follows:
mov eax, a ; Assume a and b are 32-bit integers
cmp eax, b
jne aNEb
lea rcx, aIsEqlBstr ; "a is equal to b \ n"
call printf
aNEb:In general, conditional statements may be broken into three basic categories: if statements, switch/case statements, and indirect jumps. The following sections describe these program structures, how to use them, and how to write them in assembly language.
7.6.2 if/then/else Sequences
The most common conditional statements are the if/then/endif and if/then/else/endif statements. These two statements take the form shown in Figure 7-1.
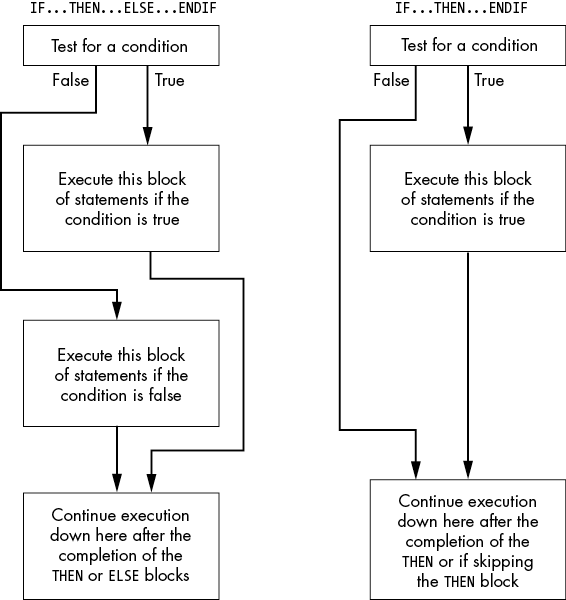
Figure 7-1: if/then/else/endif and if/then/endif statement flow
The if/then/endif statement is just a special case of the if/then/else/endif statement (with an empty else block). The basic implementation of an if/then/else/endif statement in x86-64 assembly language looks something like
Sequence of statements to test a condition
jcc ElseCode;
Sequence of statements corresponding to the THEN block
jmp EndOfIf
ElseCode:
Sequence of statements corresponding to the ELSE block
EndOfIf:where jcc represents a conditional jump instruction.
For example, to convert the C/C++ statement
if(a == b)
c = d;
else
b = b + 1;to assembly language, you could use the following x86-64 code:
mov eax, a
cmp eax, b
jne ElseBlk
mov eax, d
mov c, eax
jmp EndOfIf;
ElseBlk:
inc b
EndOfIf: For simple expressions like (a == b), generating the proper code for an if/then/else/endif statement is almost trivial. Should the expression become more complex, the code complexity increases as well. Consider the following C/C++ if statement presented earlier:
if(((x > y) && (z < t)) || (a != b))
c = d;To convert complex if statements such as this one, break it into a sequence of three if statements as follows:
if(a != b) c = d;
else if(x > y)
if(z < t)
c = d;This conversion comes from the following C/C++ equivalences:
if(expr1 && expr2) Stmt;is equivalent to
if(expr1) if(expr2) Stmt;and
if(expr1 || expr2) Stmt;is equivalent to
if(expr1) Stmt;
else if(expr2) Stmt;In assembly language, the former if statement becomes
; if(((x > y) && (z < t)) || (a != b))c = d;
mov eax, a
cmp eax, b
jne DoIf;
mov eax, x
cmp eax, y
jng EndOfIf;
mov eax, z
cmp eax, t
jnl EndOfIf;
DoIf:
mov eax, d
mov c, eax
EndOfIf:Probably the biggest problem with complex conditional statements in assembly language is trying to figure out what you’ve done after you’ve written the code. High-level language expressions are much easier to read and comprehend. Well-written comments are essential for clear assembly language implementations of if/then/else/endif statements. An elegant implementation of the preceding example follows:
; if ((x > y) && (z < t)) or (a != b) c = d;
; Implemented as:
; if (a != b) then goto DoIf:
mov eax, a
cmp eax, b
jne DoIf
; if not (x > y) then goto EndOfIf:
mov eax, x
cmp eax, y
jng EndOfIf
; if not (z < t) then goto EndOfIf:
mov eax, z
cmp eax, t
jnl EndOfIf
; THEN block:
DoIf:
mov eax, d
mov c, eax
; End of IF statement.
EndOfIf:Admittedly, this goes overboard for such a simple example. The following would probably suffice:
; if (((x > y) && (z < t)) || (a != b)) c = d;
; Test the Boolean expression:
mov eax, a
cmp eax, b
jne DoIf
mov eax, x
cmp eax, y
jng EndOfIf
mov eax, z
cmp eax, t
jnl EndOfIf
; THEN block:
DoIf:
mov eax, d
mov c, eax
; End of IF statement.
EndOfIf: However, as your if statements become complex, the density (and quality) of your comments becomes more and more important.
7.6.3 Complex if Statements Using Complete Boolean Evaluation
Many Boolean expressions involve conjunction (and) or disjunction (or) operations. This section describes how to convert such Boolean expressions into assembly language. We can do this in two ways: using complete Boolean evaluation or using short-circuit Boolean evaluation. This section discusses complete Boolean evaluation. The next section discusses short-circuit Boolean evaluation.
Conversion via complete Boolean evaluation is almost identical to converting arithmetic expressions into assembly language, as covered in Chapter 6. However, for Boolean evaluation, you do not need to store the result in a variable; once the evaluation of the expression is complete, you check whether you have a false (0) or true (1, or nonzero) result to take whatever action the Boolean expression dictates. Usually, the last logical instruction (and/or) sets the zero flag if the result is false and clears the zero flag if the result is true, so you don’t have to explicitly test for the result. Consider the following if statement and its conversion to assembly language using complete Boolean evaluation:
; if(((x < y) && (z > t)) || (a != b))
; Stmt1
mov eax, x
cmp eax, y
setl bl ; Store x < y in BL
mov eax, z
cmp eax, t
setg bh ; Store z > t in BH
and bl, bh ; Put (x < y) && (z > t) into BL
mov eax, a
cmp eax, b
setne bh ; Store a != b into BH
or bl, bh ; Put (x < y) && (z > t) || (a != b) into BL
je SkipStmt1 ; Branch if result is false
Code for Stmt1 goes here
SkipStmt1:This code computes a Boolean result in the BL register and then, at the end of the computation, tests this value to see whether it contains true or false. If the result is false, this sequence skips over the code associated with Stmt1. The important thing to note in this example is that the program will execute every instruction that computes this Boolean result (up to the je instruction).
7.6.4 Short-Circuit Boolean Evaluation
If you are willing to expend a little more effort, you can usually convert a Boolean expression to a much shorter and faster sequence of assembly language instructions by using short-circuit Boolean evaluation. This approach attempts to determine whether an expression is true or false by executing only some of the instructions that would compute the complete expression.
Consider the expression a && b. Once we determine that a is false, there is no need to evaluate b because there is no way the expression can be true. If b represents a complex subexpression rather than a single Boolean variable, it should be clear that evaluating only a is more efficient.
As a concrete example, consider the subexpression ((x < y) && (z > t)) from the previous section. Once you determine that x is not less than y, there is no need to check whether z is greater than t because the expression will be false regardless of z’s and t’s values. The following code fragment shows how you can implement short-circuit Boolean evaluation for this expression:
; if((x < y) && (z > t)) then ...
mov eax, x
cmp eax, y
jnl TestFails
mov eax, z
cmp eax, t
jng TestFails
Code for THEN clause of IF statement
TestFails:The code skips any further testing once it determines that x is not less than y. Of course, if x is less than y, the program has to test z to see if it is greater than t; if not, the program skips over the then clause. Only if the program satisfies both conditions does the code fall through to the then clause.
For the logical or operation, the technique is similar. If the first subexpression evaluates to true, there is no need to test the second operand. Whatever the second operand’s value is at that point, the full expression still evaluates to true. The following example demonstrates the use of short-circuit evaluation with disjunction (or):
; if(ch < 'A' || ch > 'Z')
; then printf("Not an uppercase char");
; endif;
cmp ch, 'A'
jb ItsNotUC
cmp ch, 'Z'
jna ItWasUC
ItsNotUC:
Code to process ch if it's not an uppercase character
ItWasUC:Because the conjunction and disjunction operators are commutative, you can evaluate the left or right operand first if it is more convenient to do so.3 As one last example in this section, consider the full Boolean expression from the previous section:
; if(((x < y) && (z > t)) || (a != b)) Stmt1 ;
mov eax, a
cmp eax, b
jne DoStmt1
mov eax, x
cmp eax, y
jnl SkipStmt1
mov eax, z
cmp eax, t
jng SkipStmt1
DoStmt1:
Code for Stmt1 goes here
SkipStmt1:The code in this example evaluates a != b first, because it is shorter and faster,4 and the remaining subexpression last. This is a common technique assembly language programmers use to write better code.5
7.6.5 Short-Circuit vs. Complete Boolean Evaluation
When using complete Boolean evaluation, every statement in the sequence for that expression will execute; short-circuit Boolean evaluation, on the other hand, may not require the execution of every statement associated with the Boolean expression. As you’ve seen in the previous two sections, code based on short-circuit evaluation is usually shorter and faster.
However, short-circuit Boolean evaluation may not produce the correct result in some cases. Given an expression with side effects, short-circuit Boolean evaluation will produce a different result than complete Boolean evaluation. Consider the following C/C++ example:
if((x == y) && (++z != 0)) Stmt ;Using complete Boolean evaluation, you might generate the following code:
mov eax, x ; See if x == y
cmp eax, y
sete bl
inc z ; ++z
cmp z, 0 ; See if incremented z is 0
setne bh
and bl, bh ; Test x == y && ++z != 0
jz SkipStmt
Code for Stmt goes here
SkipStmt:Using short-circuit Boolean evaluation, you might generate this:
mov eax, x ; See if x == y
cmp eax, y
jne SkipStmt
inc z ; ++z - sets ZF if z becomes zero
je SkipStmt ; See if incremented z is 0
Code for Stmt goes here
SkipStmt:Notice a subtle but important difference between these two conversions: if x is equal to y, the first version still increments z and compares it to 0 before it executes the code associated with Stmt; the short-circuit version, on the other hand, skips the code that increments z if it turns out that x is equal to y. Therefore, the behavior of these two code fragments is different if x is equal to y.
Neither implementation is particularly wrong; depending on the circumstances, you may or may not want the code to increment z if x is equal to y. However, it is important to realize that these two schemes produce different results, so you can choose an appropriate implementation if the effect of this code on z matters to your program.
Many programs take advantage of short-circuit Boolean evaluation and rely on the program not evaluating certain components of the expression. The following C/C++ code fragment demonstrates perhaps the most common example that requires short-circuit Boolean evaluation:
if(pntr != NULL && *pntr == 'a') Stmt ;If it turns out that pntr is NULL, the expression is false, and there is no need to evaluate the remainder of the expression. This statement relies on short-circuit Boolean evaluation for correct operation. Were C/C++ to use complete Boolean evaluation, the second half of the expression would attempt to dereference a NULL pointer, when pntr is NULL.
Consider the translation of this statement using complete Boolean evaluation:
; Complete Boolean evaluation:
mov rax, pntr
test rax, rax ; Check to see if RAX is 0 (NULL is 0)
setne bl
mov al, [rax] ; Get *pntr into AL
cmp al, 'a'
sete bh
and bl, bh
jz SkipStmt
Code for Stmt goes here
SkipStmt:If pntr contains NULL (0), this program will attempt to access the data at location 0 in memory via the mov al, [rax] instruction. Under most operating systems, this will cause a memory access fault (general protection fault).
Now consider the short-circuit Boolean conversion:
; Short-circuit Boolean evaluation:
mov rax, pntr ; See if pntr contains NULL (0) and
test rax, rax ; immediately skip past Stmt if this
jz SkipStmt ; is the case
mov al, [rax] ; If we get to this point, pntr contains
cmp al, 'a' ; a non-NULL value, so see if it points
jne SkipStmt ; at the character "a"
Code for Stmt goes here
SkipStmt:In this example, the problem with dereferencing the NULL pointer doesn’t exist. If pntr contains NULL, this code skips over the statements that attempt to access the memory address pntr contains.
7.6.6 Efficient Implementation of if Statements in Assembly Language
Encoding if statements efficiently in assembly language takes a bit more thought than simply choosing short-circuit evaluation over complete Boolean evaluation. To write code that executes as quickly as possible in assembly language, you must carefully analyze the situation and generate the code appropriately. The following paragraphs provide suggestions you can apply to your programs to improve their performance.
7.6.6.1 Know Your Data!
Programmers often mistakenly assume that data is random. In reality, data is rarely random, and if you know the types of values that your program commonly uses, you can write better code. To see how, consider the following C/C++ statement:
if((a == b) && (c < d)) ++i;Because C/C++ uses short-circuit evaluation, this code will test whether a is equal to b. If so, it will test whether c is less than d. If you expect a to be equal to b most of the time but don’t expect c to be less than d most of the time, this statement will execute slower than it should. Consider the following MASM implementation of this code:
mov eax, a
cmp eax, b
jne DontIncI
mov eax, c
cmp eax, d
jnl DontIncI
inc i
DontIncI:As you can see, if a is equal to b most of the time and c is not less than d most of the time, you will have to execute all six instructions nearly every time in order to determine that the expression is false. Now consider the following implementation that takes advantage of this knowledge and the fact that the && operator is commutative:
mov eax, c
cmp eax, d
jnl DontIncI
mov eax, a
cmp eax, b
jne DontIncI
inc i
DontIncI:The code first checks whether c is less than d. If most of the time c is less than d, this code determines that it has to skip to the label DontIncI after executing only three instructions in the typical case (compared with six instructions in the previous example).
This fact is much more obvious in assembly language than in a high-level language, one of the main reasons assembly programs are often faster than their HLL counterparts: optimizations are more obvious in assembly language than in a high-level language. Of course, the key here is to understand the behavior of your data so you can make intelligent decisions such as the preceding one.
7.6.6.2 Rearranging Expressions
Even if your data is random (or you can’t determine how the input values will affect your decisions), rearranging the terms in your expressions may still be beneficial. Some calculations take far longer to compute than others. For example, the div instruction is much slower than a simple cmp instruction. Therefore, if you have a statement like the following, you may want to rearrange the expression so that the cmp comes first:
if((x % 10 = 0) && (x != y) ++x;Converted to assembly code, this if statement becomes the following:
mov eax, x ; Compute X % 10
cdq ; Must sign-extend EAX -> EDX:EAX
idiv ten ; "ten dword 10" in .const section
test edx, edx ; Remainder is in EDX, test for 0
jnz SkipIf
mov eax, x
cmp eax, y
je SkipIf
inc x
SkipIf:The idiv instruction is expensive (often 50 to 100 times slower than most of the other instructions in this example). Unless it is 50 to 100 times more likely that the remainder is 0 rather than x is equal to y, it would be better to do the comparison first and the remainder calculation afterward:
mov eax, x
cmp eax, y
je SkipIf
mov eax, x ; Compute X % 10
cdq ; Must sign-extend EAX -> EDX:EAX
idiv ten ; "ten dword 10" in .const section
test edx, edx ; See if remainder (EDX) is 0
jnz SkipIf
inc x
SkipIf:Because the && and || operators are not commutative when short-circuit evaluation occurs, do consider such transformations carefully when making them. This example works fine because there are no side effects or possible exceptions being shielded by the reordered evaluation of the && operator.
7.6.6.3 Destructuring Your Code
Structured code is sometimes less efficient than unstructured code because it introduces code duplication or extra branches that might not be present in unstructured code.6 Most of the time, this is tolerable because unstructured code is difficult to read and maintain; sacrificing some performance in exchange for maintainable code is often acceptable. In certain instances, however, you may need all the performance you can get and might choose to compromise the readability of your code.
Taking previously written structured code and rewriting it in an unstructured fashion to improve performance is known as destructuring code. The difference between unstructured code and destructured code is that unstructured code was written that way in the first place; destructured code started out as structured code and was purposefully written in an unstructured fashion to make it more efficient. Pure unstructured code is usually hard to read and maintain. Destructured code isn’t quite as bad because you limit the damage (unstructuring the code) to only those sections where it is absolutely necessary.
One classic way to destructure code is to use code movement (physically moving sections of code elsewhere in the program) to move code that your program rarely uses out of the way of code that executes most of the time. Code movement can improve the efficiency of a program in two ways.
First, a branch that is taken is more expensive (time-consuming) than a branch that is not taken.7 If you move the rarely used code to another spot in the program and branch to it on the rare occasion the branch is taken, most of the time you will fall straight through to the code that executes most frequently.
Second, sequential machine instructions consume cache storage. If you move rarely executed statements out of the normal code stream to another section of the program (that is rarely loaded into cache), this will improve the cache performance of the system.
For example, consider the following pseudo C/C++ statement:
if(see_if_an_error_has_occurred)
{
Statements to execute if no error
}
else
{
Error-handling statements
}In normal code, we don’t expect errors to be frequent. Therefore, you would normally expect the then section of the preceding if to execute far more often than the else clause. The preceding code could translate into the following assembly code:
cmp see_if_an_error_has_occurred, true
je HandleTheError
Statements to execute if no error
jmp EndOfIf;
HandleTheError:
Error-handling statements
EndOfIf:If the expression is false, this code falls through to the normal statements and then jumps over the error-handling statements. Instructions that transfer control from one point in your program to another (for example, jmp instructions) tend to be slow. It is much faster to execute a sequential set of instructions rather than jump all over the place in your program. Unfortunately, the preceding code doesn’t allow this.
One way to rectify this problem is to move the else clause of the code somewhere else in your program. You could rewrite the code as follows:
cmp see_if_an_error_has_occurred, true
je HandleTheError
Statements to execute if no error
EndOfIf:At some other point in your program (typically after a jmp instruction), you would insert the following code:
HandleTheError:
Error-handling statements
jmp EndOfIf;The program isn’t any shorter. The jmp you removed from the original sequence winds up at the end of the else clause. However, because the else clause rarely executes, moving the jmp instruction from the then clause (which executes frequently) to the else clause is a big performance win because the then clause executes using only straight-line code. This technique is surprisingly effective in many time-critical code segments.
7.6.6.4 Calculation Rather Than Branching
On many processors in the x86-64 family, branches (jumps) are expensive compared to many other instructions. For this reason, it is sometimes better to execute more instructions in a sequence than fewer instructions that involve branching.
For example, consider the simple assignment eax = abs(eax). Unfortunately, no x86-64 instruction computes the absolute value of an integer. The obvious way to handle this is with an instruction sequence that uses a conditional jump to skip over the neg instruction (which creates a positive value in EAX if EAX was negative):
test eax, eax
jns ItsPositive;
neg eax
ItsPositive:Now consider the following sequence that will also do the job:
; Set EDX to 0FFFF_FFFFh if EAX is negative, 0000_0000 if EAX is
; 0 or positive:
cdq
; If EAX was negative, the following code inverts all the bits in
; EAX; otherwise, it has no effect on EAX.
xor eax, edx
; If EAX was negative, the following code adds 1 to EAX;
; otherwise, it doesn't modify EAX's value.
and edx, 1 ; EDX = 0 or 1 (1 if EAX was negative)
add eax, edxThis code will invert all the bits in EAX and then add 1 to EAX if EAX was negative prior to the sequence; that is, it negates the value in EAX. If EAX was zero or positive, this code does not change the value in EAX.
Though this sequence takes four instructions rather than the three that the previous example requires, there are no transfer-of-control instructions, so it may execute faster on many CPUs in the x86-64 family. Of course, if you use the cmovns instruction presented earlier, this can be done with the following three instructions (with no transfer of control):
mov edx, eax
neg edx
cmovns eax, edx This demonstrates why it’s good to know the instruction set!
7.6.7 switch/case Statements
The C/C++ switch statement takes the following form:
switch(expression)
{
case const1:
Stmts1: Code to execute if
expression equals const1
case const2:
Stmts2: Code to execute if
expression equals const2
.
.
.
case constn:
Stmtsn: Code to execute if
expression equals constn
default: ; Note that the default section is optional
Stmts_default: Code to execute if expression
does not equal
any of the case values
}When this statement executes, it checks the value of the expression against the constants const1 to constn. If it finds a match, the corresponding statements execute.
C/C++ places a few restrictions on the switch statement. First, the switch statement allows only an integer expression (or something whose underlying type can be an integer). Second, all the constants in the case clauses must be unique. The reason for these restrictions will become clear in a moment.
7.6.7.1 switch Statement Semantics
Most introductory programming texts introduce the switch/case statement by explaining it as a sequence of if/then/elseif/else/endif statements. They might claim that the following two pieces of C/C++ code are equivalent:
switch(expression)
{
case 0: printf("i=0"); break;
case 1: printf("i=1"); break;
case 2: printf("i=2"); break;
}
if(eax == 0)
printf("i=0");
else if(eax == 1)
printf("i=1");
else if(eax == 2)
printf("i=2");While semantically these two code segments may be the same, their implementation is usually different. Whereas the if/then/elseif/else/endif chain does a comparison for each conditional statement in the sequence, the switch statement normally uses an indirect jump to transfer control to any one of several statements with a single computation.
7.6.7.2 if/else Implementation of switch
The switch (and if/else/elseif) statements could be written in assembly language with the following code:
; if/then/else/endif form:
mov eax, i
test eax, eax ; Check for 0
jnz Not0
Code to print "i = 0"
jmp EndCase
Not0:
cmp eax, 1
jne Not1
Code to print "i = 1"
jmp EndCase
Not1:
cmp eax, 2
jne EndCase;
Code to print "i = 2"
EndCase: Probably the only thing worth noting about this code is that it takes longer to determine the last case than it does to determine whether the first case executes. This is because the if/else/elseif version implements a linear search through the case values, checking them one at a time from first to last until it finds a match.
7.6.7.3 Indirect Jump switch Implementation
A faster implementation of the switch statement is possible using an indirect jump table. This implementation uses the switch expression as an index into a table of addresses; each address points at the target case’s code to execute. Consider the following example:
; Indirect Jump Version.
mov eax, i
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8]
JmpTbl qword Stmt0, Stmt1, Stmt2
Stmt0:
Code to print "i = 0"
jmp EndCase;
Stmt1:
Code to print "i = 1"
jmp EndCase;
Stmt2:
Code to print "i = 2"
EndCase: To begin with, a switch statement requires that you create an array of pointers with each element containing the address of a statement label in your code (those labels must be attached to the sequence of instructions to execute for each case in the switch statement). In the preceding example, the JmpTbl array, initialized with the address of the statement labels Stmt0, Stmt1, and Stmt2, serves this purpose. I’ve placed this array in the procedure itself because the labels are local to the procedure. Note, however, that you must place the array in a location that will never be executed as code (such as immediately after a jmp instruction, as in this example).
The program loads the RAX register with i’s value (assuming i is a 32-bit integer, the mov instruction zero-extends EAX into RAX), then uses this value as an index into the JmpTbl array (RCX holds the base address of the JmpTbl array) and transfers control to the 8-byte address found at the specified location. For example, if RAX contains 0, the jmp [rcx][rax * 8] instruction will fetch the quad word at address JmpTbl+0 (RAX × 8 = 0). Because the first quad word in the table contains the address of Stmt0, the jmp instruction transfers control to the first instruction following the Stmt0 label. Likewise, if i (and therefore, RAX) contains 1, then the indirect jmp instruction fetches the quad word at offset 8 from the table and transfers control to the first instruction following the Stmt1 label (because the address of Stmt1 appears at offset 8 in the table). Finally, if i / RAX contains 2, then this code fragment transfers control to the statements following the Stmt2 label because it appears at offset 16 in the JmpTbl table.
As you add more (consecutive) cases, the jump table implementation becomes more efficient (in terms of both space and speed) than the if/elseif form. Except for simple cases, the switch statement is almost always faster, and usually by a large margin. As long as the case values are consecutive, the switch statement version is usually smaller as well.
7.6.7.4 Noncontiguous Jump Table Entries and Range Limiting
What happens if you need to include nonconsecutive case labels or cannot be sure that the switch value doesn’t go out of range? With the C/C++ switch statement, such an occurrence will transfer control to the first statement after the switch statement (or to a default case, if one is present in the switch).
However, this doesn’t happen in the preceding example. If variable i does not contain 0, 1, or 2, executing the previous code produces undefined results. For example, if i contains 5 when you execute the code, the indirect jmp instruction will fetch the qword at offset 40 (5 × 8) in JmpTbl and transfer control to that address. Unfortunately, JmpTbl doesn’t have six entries, so the program will fetch the value of the sixth quad word following JmpTbl and use that as the target address, which will often crash your program or transfer control to an unexpected location.
The solution is to place a few instructions before the indirect jmp to verify that the switch selection value is within a reasonable range. In the previous example, we’d probably want to verify that i’s value is in the range 0 to 2 before executing the jmp instruction. If i’s value is outside this range, the program should simply jump to the endcase label (this corresponds to dropping down to the first statement after the entire switch statement). The following code provides this modification:
mov eax, i
cmp eax, 2
ja EndCase
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8]
JmpTbl qword Stmt0, Stmt1, Stmt2
Stmt0:
Code to print "i = 0"
jmp EndCase;
Stmt1:
Code to print "i = 1"
jmp EndCase;
Stmt2:
Code to print "i = 2"
EndCase:Although the preceding example handles the problem of selection values being outside the range 0 to 2, it still suffers from a couple of severe restrictions:
- The cases must start with the value 0. That is, the minimum
caseconstant has to be 0 in this example. - The case values must be contiguous.
Solving the first problem is easy, and you deal with it in two steps. First, you compare the case selection value against a lower and upper bound before determining if the case value is legal. For example:
; SWITCH statement specifying cases 5, 6, and 7:
; WARNING: This code does *NOT* work.
; Keep reading to find out why.
mov eax, i
cmp eax, 5
jb EndCase
cmp eax, 7 ; Verify that i is in the range
ja EndCase ; 5 to 7 before the indirect jmp
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8]
JmpTbl qword Stmt5, Stmt6, Stmt7
Stmt5:
Code to print "i = 5"
jmp EndCase;
Stmt6:
Code to print "i = 6"
jmp EndCase;
Stmt7:
Code to print "i = 7"
EndCase:This code adds a pair of extra instructions, cmp and jb, to test the selection value to ensure it is in the range 5 to 7. If not, control drops down to the EndCase label; otherwise, control transfers via the indirect jmp instruction. Unfortunately, as the comments point out, this code is broken.
Consider what happens if variable i contains the value 5: the code will verify that 5 is in the range 5 to 7 and then will fetch the dword at offset 40 (5 × 8) and jump to that address. As before, however, this loads 8 bytes outside the bounds of the table and does not transfer control to a defined location. One solution is to subtract the smallest case selection value from EAX before executing the jmp instruction, as shown in the following example:
; SWITCH statement specifying cases 5, 6, and 7.
; WARNING: There is a better way to do this; keep reading.
mov eax, i
cmp eax, 5
jb EndCase
cmp eax, 7 ; Verify that i is in the range
ja EndCase ; 5 to 7 before the indirect jmp
sub eax, 5 ; 5 to 7 -> 0 to 2
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8]
JmpTbl qword Stmt5, Stmt6, Stmt7
Stmt5:
Code to print "i = 5"
jmp EndCase;
Stmt6:
Code to print "i = 6"
jmp EndCase;
Stmt7:
Code to print "i = 7"
EndCase: By subtracting 5 from the value in EAX, we force EAX to take on the value 0, 1, or 2 prior to the jmp instruction. Therefore, case-selection value 5 jumps to Stmt5, case-selection value 6 transfers control to Stmt6, and case-selection value 7 jumps to Stmt7.
To improve this code, you can eliminate the sub instruction by merging it into the jmp instruction’s address expression. The following code does this:
; SWITCH statement specifying cases 5, 6, and 7:
mov eax, i
cmp eax, 5
jb EndCase
cmp eax, 7 ; Verify that i is in the range
ja EndCase ; 5 to 7 before the indirect jmp
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8 – 5 * 8] ; 5 * 8 compensates for zero index
JmpTbl qword Stmt5, Stmt6, Stmt7
Stmt5:
Code to print "i = 5"
jmp EndCase;
Stmt6:
Code to print "i = 6"
jmp EndCase;
Stmt7:
Code to print "i = 7"
EndCase:The C/C++ switch statement provides a default clause that executes if the case-selection value doesn’t match any of the case values. For example:
switch(expression)
{
case 5: printf("ebx = 5"); break;
case 6: printf("ebx = 6"); break;
case 7: printf("ebx = 7"); break;
default
printf("ebx does not equal 5, 6, or 7");
}Implementing the equivalent of the default clause in pure assembly language is easy. Just use a different target label in the jb and ja instructions at the beginning of the code. The following example implements a MASM switch statement similar to the preceding one:
; SWITCH statement specifying cases 5, 6, and 7
; with a DEFAULT clause:
mov eax, i
cmp eax, 5
jb DefaultCase
cmp eax, 7 ; Verify that i is in the range
ja DefaultCase ; 5 to 7 before the indirect jmp
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8 – 5 * 8] ; 5 * 8 compensates for zero index
JmpTbl qword Stmt5, Stmt6, Stmt7
Stmt5:
Code to print "i = 5"
jmp EndCase
Stmt6:
Code to print "i = 6"
jmp EndCase
Stmt7:
Code to print "i = 7"
jmp EndCase
DefaultCase:
Code to print "EBX does not equal 5, 6, or 7"
EndCase:The second restriction noted earlier, (that is, the case values need to be contiguous) is easy to handle by inserting extra entries into the jump table. Consider the following C/C++ switch statement:
switch(i)
{
case 1 printf("i = 1"); break;
case 2 printf("i = 2"); break;
case 4 printf("i = 4"); break;
case 8 printf("i = 8"); break;
default:
printf("i is not 1, 2, 4, or 8");
}The minimum switch value is 1, and the maximum value is 8. Therefore, the code before the indirect jmp instruction needs to compare the value in i against 1 and 8. If the value is between 1 and 8, it’s still possible that i might not contain a legal case-selection value. However, because the jmp instruction indexes into a table of quad words using the case-selection table, the table must have eight quad-word entries.
To handle the values between 1 and 8 that are not case-selection values, simply put the statement label of the default clause (or the label specifying the first instruction after the endswitch if there is no default clause) in each of the jump table entries that don’t have a corresponding case clause. The following code demonstrates this technique:
; SWITCH statement specifying cases 1, 2, 4, and 8
; with a DEFAULT clause:
mov eax, i
cmp eax, 1
jb DefaultCase
cmp eax, 8 ; Verify that i is in the range
ja DefaultCase ; 1 to 8 before the indirect jmp
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8 – 1 * 8] ; 1 * 8 compensates for zero index
JmpTbl qword Stmt1, Stmt2, DefaultCase, Stmt4
qword DefaultCase, DefaultCase, DefaultCase, Stmt8
Stmt1:
Code to print "i = 1"
jmp EndCase
Stmt2:
Code to print "i = 2"
jmp EndCase
Stmt4:
Code to print "i = 4"
jmp EndCase
Stmt8:
Code to print "i = 8"
jmp EndCase
DefaultCase:
Code to print "i does not equal 1, 2, 4, or 8"
EndCase: 7.6.7.5 Sparse Jump Tables
The current implementation of the switch statement has a problem. If the case values contain nonconsecutive entries that are widely spaced, the jump table could become exceedingly large. The following switch statement would generate an extremely large code file:
switch(i)
{
case 1: Stmt1 ;
case 100: Stmt2 ;
case 1000: Stmt3 ;
case 10000: Stmt4 ;
default: Stmt5 ;
}In this situation, your program will be much smaller if you implement the switch statement with a sequence of if statements rather than using an indirect jump statement. However, keep one thing in mind: the size of the jump table does not normally affect the execution speed of the program. If the jump table contains two entries or two thousand, the switch statement will execute the multiway branch in a constant amount of time. The if statement implementation requires a linearly increasing amount of time for each case label appearing in the case statement.
Probably the biggest advantage to using assembly language over an HLL like Pascal or C/C++ is that you get to choose the actual implementation of statements like switch. In some instances, you can implement a switch statement as a sequence of if/then/elseif statements, or you can implement it as a jump table, or you can use a hybrid of the two:
switch(i)
{
case 0: Stmt0 ;
case 1: Stmt1 ;
case 2: Stmt2 ;
case 100: Stmt3 ;
default: Stmt4 ;
}That could become the following:
mov eax, i
cmp eax, 100
je DoStmt3;
cmp eax, 2
ja TheDefaultCase
lea rcx, JmpTbl
jmp qword ptr [rcx][rax * 8]
.
.
.If you are willing to live with programs that cannot exceed 2GB in size (and use the LARGEADDRESSAWARE:NO command line option), you can improve the implementation of the switch statement and save one instruction:
; SWITCH statement specifying cases 5, 6, and 7
; with a DEFAULT clause:
mov eax, i
cmp eax, 5
jb DefaultCase
cmp eax, 7 ; Verify that i is in the range
ja DefaultCase ; 5 to 7 before the indirect jmp
jmp JmpTbl[rax * 8 – 5 * 8] ; 5 * 8 compensates for zero index
JmpTbl qword Stmt5, Stmt6, Stmt7
Stmt5:
Code to print "i = 5"
jmp EndCase
Stmt6:
Code to print "i = 6"
jmp EndCase
Stmt7:
Code to print "i = 7"
jmp EndCase
DefaultCase:
Code to print "EBX does not equal 5, 6, or 7"
EndCase:This code removed the lea rcx, JmpTbl instruction and replaced jmp [rcx][rax * 8 – 5 * 8] with jmp JmpTbl[rax * 8 – 5 * 8]. This is a small improvement, but an improvement nonetheless (this sequence not only is one instruction shorter but also uses one less register). Of course, constantly be aware of the danger of writing 64-bit programs that are not large-address aware.
Some switch statements have sparse cases but with groups of contiguous cases within the overall set of cases. Consider the following C/C++ switch statement:
switch(expression)
{
case 0:
Code for case 0
break;
case 1:
Code for case 1
break;
case 2:
Code for case 2
break;
case 10:
Code for case 10
break;
case 11:
Code for case 11
break;
case 100:
Code for case 100
break;
case 101:
Code for case 101
break;
case 103:
Code for case 101
break;
case 1000:
Code for case 1000
break;
case 1001:
Code for case 1001
break;
case 1003:
Code for case 1001
break;
default:
Code for default case
break;
} // end switchYou can convert a switch statement that consists of widely separated groups of (nearly) contiguous cases to assembly language code using one jump table implementation for each contiguous group, and you can then use compare instructions to determine which jump table instruction sequence to execute. Here’s one possible implementation of the previous C/C++ code:
; Assume expression has been computed and is sitting in EAX/RAX
; at this point...
cmp eax, 100
jb try0_11
cmp eax, 103
ja try1000_1003
cmp eax, 100
jb default
lea rcx, jt100
jmp qword ptr [rcx][rax * 8 – 100 * 8]
jt100 qword case100, case101, default, case103
try0_11: cmp ecx, 11 ; Handle cases 0-11 here
ja defaultCase
lea rcx, jt0_11
jmp qword ptr [rcx][rax * 8]
jt0_11 qword case0, case1, case2, defaultCase
qword defaultCase, defaultCase, defaultCase
qword defaultCase, defaultCase, defaultCase
qword case10, case11
try1000_1003:
cmp eax, 1000
jb defaultCase
cmp eax, 1003
ja defaultCase
lea rcx, jt1000
jmp qword ptr [rcx][rax * 8 – 1000 * 8]
jt1000 qword case1000, case1001, defaultCase, case1003
.
.
.
Code for the actual cases hereThis code sequence combines groups 0 to 2 and 10 to 11 into a single group (requiring seven additional jump table entries) in order to save having to write an additional jump table sequence.
Of course, for a set of cases this simple, it’s probably easier to just use compare-and-branch sequences. This example was simplified a bit just to make a point.
7.6.7.6 Other switch Statement Alternatives
What happens if the cases are too sparse to do anything but compare the expression’s value case by case? Is the code doomed to being translated into the equivalent of an if/elseif/else/endif sequence? Not necessarily. However, before we consider other alternatives, it’s important to mention that not all if/elseif/else/endif sequences are created equal. Look back at the previous example. A straightforward implementation might have been something like this:
if(unsignedExpression <= 11)
{
Switch for 0 to 11
}
else if(unsignedExpression >= 100 && unsignedExpression <= 101)
{
Switch for 100 to 101
}
else if(unsignedExpression >= 1000 && unsignedExpression <= 1001)
{
Switch for 1000 to 1001
}
else
{
Code for default case
}Instead, the former implementation first tests against the value 100 and branches based on the comparison being less than (cases 0 to 11) or greater than (cases 1000 to 1001), effectively creating a small binary search that reduces the number of comparisons. It’s hard to see the savings in the HLL code, but in assembly code you can count the number of instructions that would be executed in the best and worst cases and see an improvement over the standard linear search approach of simply comparing the values in the cases in the order they appear in the switch statement.8
If your cases are too sparse (no meaningful groups at all), such as the 1, 10, 100, 1000, 10,000 example given earlier in this chapter, you’re not going to be able to (reasonably) implement the switch statement by using a jump table. Rather than devolving into a straight linear search (which can be slow), a better solution is to sort your cases and test them using a binary search.
With a binary search, you first compare the expression value against the middle case value. If it’s less than the middle value, you repeat the search on the first half of the list of values; if it’s greater than the middle value, you repeat the test on the second half of the values; if it’s equal, obviously you drop into the code to handle that test. Here’s the binary search version of the 1, 10, 100, . . . example:
; Assume expression has been calculated into EAX.
cmp eax, 100
jb try1_10
ja try1000_10000
Code to handle case 100 goes here
jmp AllDone
try1_10:
cmp eax,1
je case1
cmp eax, 10
jne defaultCase
Code to handle case 10 goes here
jmp AllDone
case1:
Code to handle case 1 goes here
jmp AllDone
try1000_10000:
cmp eax, 1000
je case1000
cmp eax, 10000
jne defaultCase
Code to handle case 10000 goes here
jmp AllDone
case1000:
Code to handle case 1000 goes here
jmp AllDone
defaultCase:
Code to handle defaultCase goes here
AllDone:The techniques presented in this section have many possible alternatives. For example, one common solution is to create a table containing a set of records (structures), with each record entry a two-tuple containing a case value and a jump address. Rather than having a long sequence of compare instructions, a short loop can sequence through all the table elements, searching for the case value and transferring control to the corresponding jump address if there is a match. This scheme is slower than the other techniques in this section but can be much shorter than the traditional if/elseif/else/endif implementation.9
Note, by the way, that the defaultCase label often appears in several jcc instructions in a (non-jump-table) switch implementation. Since the conditional jump instructions have two encodings, a 2-byte form and a 6-byte form, you should try to place the defaultCase near these conditional jumps so you can use the short form of the instruction as much as possible. Although the examples in this section have typically put the jump tables (which consume a large number of bytes) immediately after their corresponding indirect jump, you could move these tables elsewhere in the procedure to help keep the conditional jump instructions short. Here’s the earlier 1, 10, 100, . . . example coded with this in mind:
; Assume expression has been computed and is sitting in EAX/RAX
; at this point...
cmp eax, 100
jb try0_13
cmp eax, 103
ja try1000_1003
lea rcx, jt100
jmp qword ptr [rcx][rax * 8 – 100 * 8]
try0_13: cmp ecx, 13 ; Handle cases 0 to 13 here
ja defaultCase
lea rcx, jt0_13
jmp qword ptr [rcx][rax * 8]
try1000_1003:
cmp eax, 1000 ; Handle cases 1000 to 1003 here
jb defaultCase
cmp eax, 1003
ja defaultCase
lea rcx, jt1000
jmp qword ptr [rcx][rax * 8 – 1000 * 8]
defaultCase:
Put defaultCase here to keep it near all the
conditional jumps to defaultCase
jmp AllDone
jt0_13 qword case0, case1, case2, case3
qword defaultCase, defaultCase, defaultCase
qword defaultCase, defaultCase, defaultCase
qword case10, case11, case12, case13
jt100 qword case100, case101, case102, case103
jt1000 qword case1000, case1001, case1002, case1003
.
.
.
Code for the actual cases here7.7 State Machines and Indirect Jumps
Another control structure commonly found in assembly language programs is the state machine. A state machine uses a state variable to control program flow. The FORTRAN programming language provides this capability with the assigned goto statement. Certain variants of C (for example, GNU’s GCC from the Free Software Foundation) provide similar features. In assembly language, the indirect jump can implement state machines.
So what is a state machine? In basic terms, it is a piece of code that keeps track of its execution history by entering and leaving certain states. For the purposes of this chapter, we’ll just assume that a state machine is a piece of code that (somehow) remembers the history of its execution (its state) and executes sections of code based on that history.
In a real sense, all programs are state machines. The CPU registers and values in memory constitute the state of that machine. However, we’ll use a much more constrained view. Indeed, for most purposes, only a single variable (or the value in the RIP register) will denote the current state.
Now let’s consider a concrete example. Suppose you have a procedure and want to perform one operation the first time you call it, a different operation the second time you call it, yet something else the third time you call it, and then something new again on the fourth call. After the fourth call, it repeats these four operations in order.
For example, suppose you want the procedure to add EAX and EBX the first time, subtract them on the second call, multiply them on the third, and divide them on the fourth. You could implement this procedure as shown in Listing 7-6.
; Listing 7-6
; A simple state machine example.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 7-6", 0
fmtStr0 byte "Calling StateMachine, "
byte "state=%d, EAX=5, ECX=6", nl, 0
fmtStr0b byte "Calling StateMachine, "
byte "state=%d, EAX=1, ECX=2", nl, 0
fmtStrx byte "Back from StateMachine, "
byte "state=%d, EAX=%d", nl, 0
fmtStr1 byte "Calling StateMachine, "
byte "state=%d, EAX=50, ECX=60", nl, 0
fmtStr2 byte "Calling StateMachine, "
byte "state=%d, EAX=10, ECX=20", nl, 0
fmtStr3 byte "Calling StateMachine, "
byte "state=%d, EAX=50, ECX=5", nl, 0
.data
state byte 0
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
StateMachine proc
cmp state, 0
jne TryState1
; State 0: Add ECX to EAX and switch to state 1:
add eax, ecx
inc state ; State 0 becomes state 1
jmp exit
TryState1:
cmp state, 1
jne TryState2
; State 1: Subtract ECX from EAX and switch to state 2:
sub eax, ecx
inc state ; State 1 becomes state 2
jmp exit
TryState2: cmp state, 2
jne MustBeState3
; If this is state 2, multiply ECX by EAX and switch to state 3:
imul eax, ecx
inc state ; State 2 becomes state 3
jmp exit
; If it isn't one of the preceding states, we must be in state 3,
; so divide EAX by ECX and switch back to state 0.
MustBeState3:
push rdx ; Preserve this 'cause it
; gets whacked by div
xor edx, edx ; Zero-extend EAX into EDX
div ecx
pop rdx ; Restore EDX's value preserved above
mov state, 0 ; Reset the state back to 0
exit: ret
StateMachine endp
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 48 ; Shadow storage
mov state, 0 ; Just to be safe
; Demonstrate state 0:
lea rcx, fmtStr0
movzx rdx, state
call printf
mov eax, 5
mov ecx, 6
call StateMachine
lea rcx, fmtStrx
mov r8, rax
movzx edx, state
call printf
; Demonstrate state 1:
lea rcx, fmtStr1
movzx rdx, state
call printf
mov eax, 50
mov ecx, 60
call StateMachine
lea rcx, fmtStrx
mov r8, rax
movzx edx, state
call printf
; Demonstrate state 2:
lea rcx, fmtStr2
movzx rdx, state
call printf
mov eax, 10
mov ecx, 20
call StateMachine
lea rcx, fmtStrx
mov r8, rax
movzx edx, state
call printf
; Demonstrate state 3:
lea rcx, fmtStr3
movzx rdx, state
call printf
mov eax, 50
mov ecx, 5
call StateMachine
lea rcx, fmtStrx
mov r8, rax
movzx edx, state
call printf
; Demonstrate back in state 0:
lea rcx, fmtStr0b
movzx rdx, state
call printf
mov eax, 1
mov ecx, 2
call StateMachine
lea rcx, fmtStrx
mov r8, rax
movzx edx, state
call printf
leave
ret ; Returns to caller
asmMain endp
endListing 7-6: A state machine example
Here’s the build command and program output:
C:\>build listing7-6
C:\>echo off
Assembling: listing7-6.asm
c.cpp
C:\>listing7-6
Calling Listing 7-6:
Calling StateMachine, state=0, EAX=5, ECX=6
Back from StateMachine, state=1, EAX=11
Calling StateMachine, state=1, EAX=50, ECX=60
Back from StateMachine, state=2, EAX=-10
Calling StateMachine, state=2, EAX=10, ECX=20
Back from StateMachine, state=3, EAX=200
Calling StateMachine, state=3, EAX=50, ECX=5
Back from StateMachine, state=0, EAX=10
Calling StateMachine, state=0, EAX=1, ECX=2
Back from StateMachine, state=1, EAX=3
Listing 7-6 terminatedTechnically, this procedure is not the state machine. Instead, the variable state and the cmp/jne instructions constitute the state machine. The procedure is little more than a switch statement implemented via the if/then/elseif construct. The only unique thing is that it remembers how many times it has been called10 and behaves differently depending upon the number of calls.
While this is a correct implementation of the desired state machine, it is not particularly efficient. The astute reader, of course, would recognize that this code could be made a little faster using an actual switch statement rather than the if/then/elseif/endif implementation. However, an even better solution exists.
It’s common to use an indirect jump to implement a state machine in assembly language. Rather than having a state variable that contains a value like 0, 1, 2, or 3, we could load the state variable with the address of the code to execute upon entry into the procedure. By simply jumping to that address, the state machine could save the tests needed to select the proper code fragment. Consider the implementation in Listing 7-7 using the indirect jump.
; Listing 7-7
; An indirect jump state machine example.
option casemap:none
nl = 10
.const
ttlStr byte "Listing 7-7", 0
fmtStr0 byte "Calling StateMachine, "
byte "state=0, EAX=5, ECX=6", nl, 0
fmtStr0b byte "Calling StateMachine, "
byte "state=0, EAX=1, ECX=2", nl, 0
fmtStrx byte "Back from StateMachine, "
byte "EAX=%d", nl, 0
fmtStr1 byte "Calling StateMachine, "
byte "state=1, EAX=50, ECX=60", nl, 0
fmtStr2 byte "Calling StateMachine, "
byte "state=2, EAX=10, ECX=20", nl, 0
fmtStr3 byte "Calling StateMachine, "
byte "state=3, EAX=50, ECX=5", nl, 0
.data
state qword state0
.code
externdef printf:proc
; Return program title to C++ program:
public getTitle
getTitle proc
lea rax, ttlStr
ret
getTitle endp
; StateMachine version 2.0 - using an indirect jump.
option noscoped ; statex labels must be global
StateMachine proc
jmp state
; State 0: Add ECX to EAX and switch to state 1:
state0: add eax, ecx
lea rcx, state1
mov state, rcx
ret
; State 1: Subtract ECX from EAX and switch to state 2:
state1: sub eax, ecx
lea rcx, state2
mov state, rcx
ret
; If this is state 2, multiply ECX by EAX and switch to state 3:
state2: imul eax, ecx
lea rcx, state3
mov state, rcx
ret
state3: push rdx ; Preserve this 'cause it
; gets whacked by div
xor edx, edx ; Zero-extend EAX into EDX
div ecx
pop rdx ; Restore EDX's value preserved above
lea rcx, state0
mov state, rcx
ret
StateMachine endp
option scoped
; Here is the "asmMain" function.
public asmMain
asmMain proc
push rbp
mov rbp, rsp
sub rsp, 48 ; Shadow storage
lea rcx, state0
mov state, rcx ; Just to be safe
; Demonstrate state 0:
lea rcx, fmtStr0
call printf
mov eax, 5
mov ecx, 6
call StateMachine
lea rcx, fmtStrx
mov rdx, rax
call printf
; Demonstrate state 1:
lea rcx, fmtStr1
call printf
mov eax, 50
mov ecx, 60
call StateMachine
lea rcx, fmtStrx
mov rdx, rax
call printf
; Demonstrate state 2:
lea rcx, fmtStr2
call printf
mov eax, 10
mov ecx, 20
call StateMachine
lea rcx, fmtStrx
mov rdx, rax
call printf
; Demonstrate state 3:
lea rcx, fmtStr3
call printf
mov eax, 50
mov ecx, 5
call StateMachine
lea rcx, fmtStrx
mov rdx, rax
call printf
; Demonstrate back in state 0:
lea rcx, fmtStr0b
call printf
mov eax, 1
mov ecx, 2
call StateMachine
lea rcx, fmtStrx
mov rdx, rax
call printf
leave
ret ; Returns to caller
asmMain endp
endListing 7-7: A state machine using an indirect jump
Here’s the build command and program output:
C:\>build listing7-7
C:\>echo off
Assembling: listing7-7.asm
c.cpp
C:\>listing7-7
Calling Listing 7-7:
Calling StateMachine, state=0, EAX=5, ECX=6
Back from StateMachine, EAX=11
Calling StateMachine, state=1, EAX=50, ECX=60
Back from StateMachine, EAX=-10
Calling StateMachine, state=2, EAX=10, ECX=20
Back from StateMachine, EAX=200
Calling StateMachine, state=3, EAX=50, ECX=5
Back from StateMachine, EAX=10
Calling StateMachine, state=0, EAX=1, ECX=2
Back from StateMachine, EAX=3
Listing 7-7 terminatedThe jmp instruction at the beginning of the StateMachine procedure transfers control to the location pointed at by the state variable. The first time you call StateMachine, it points at the State0 label. Thereafter, each subsection of code sets the state variable to point at the appropriate successor code.
7.8 Loops
Loops represent the final basic control structure (sequences, decisions, and loops) that make up a typical program. As with so many other structures in assembly language, you’ll find yourself using loops in places you’ve never dreamed of using loops.
Most HLLs have implied loop structures hidden away. For example, consider the BASIC statement if A$ = B$ then 100. This if statement compares two strings and jumps to statement 100 if they are equal. In assembly language, you would need to write a loop to compare each character in A$ to the corresponding character in B$ and then jump to statement 100 if and only if all the characters matched.11
Program loops consist of three components: an optional initialization component, an optional loop-termination test, and the body of the loop. The order in which you assemble these components can dramatically affect the loop’s operation. Three permutations of these components appear frequently in programs: while loops, repeat/until loops (do/while in C/C++), and infinite loops (for example, for(;;) in C/C++).
7.8.1 while Loops
The most general loop is the while loop. In C/C++, it takes the following form:
while(expression) statement(s);In the while loop, the termination test appears at the beginning of the loop. As a direct consequence of the position of the termination test, the body of the loop may never execute if the Boolean expression is always false.
Consider the following C/C++ while loop:
i = 0;
while(i < 100)
{
++i;
}The i = 0; statement is the initialization code for this loop. i is a loop-control variable, because it controls the execution of the body of the loop. i < 100 is the loop-termination condition: the loop will not terminate as long as i is less than 100. The single statement ++i; (increment i) is the loop body that executes on each loop iteration.
A C/C++ while loop can be easily synthesized using if and goto statements. For example, you may replace the previous C while loop with the following C code:
i = 0;
WhileLp:
if(i < 100)
{
++i;
goto WhileLp;
}More generally, you can construct any while loop as follows:
Optional initialization code
UniqueLabel:
if(not_termination_condition)
{
Loop body
goto UniqueLabel;
}Therefore, you can use the techniques from earlier in this chapter to convert if statements to assembly language and add a single jmp instruction to produce a while loop. The example in this section translates to the following pure x86-64 assembly code:12
mov i, 0
WhileLp:
cmp i, 100
jnl WhileDone
inc i
jmp WhileLp;
WhileDone:7.8.2 repeat/until Loops
The repeat/until (do/while) loop tests for the termination condition at the end of the loop rather than at the beginning. In Pascal, the repeat/until loop takes the following form:
Optional initialization code
repeat
Loop body
until(termination_condition);This is comparable to the following C/C++ do/while loop:
Optional initialization code
do
{
Loop body
}while(not_termination_condition);This sequence executes the initialization code, then executes the loop body, and finally tests a condition to see whether the loop should repeat. If the Boolean expression evaluates to false, the loop repeats; otherwise, the loop terminates. The two things you should note about the repeat/until loop are that the termination test appears at the end of the loop and, as a direct consequence, the loop body always executes at least once.
Like the while loop, the repeat/until loop can be synthesized with an if statement and a jmp. You could use the following:
Initialization code
SomeUniqueLabel:
Loop body
if(not_termination_condition) goto SomeUniqueLabel;Based on the material presented in the previous sections, you can easily synthesize repeat/until loops in assembly language. The following is a simple example:
repeat (Pascal code)
write('Enter a number greater than 100:');
readln(i);
until(i > 100);
// This translates to the following if/jmp code:
RepeatLabel:
write('Enter a number greater than 100:');
readln(i);
if(i <= 100) then goto RepeatLabel;
// It also translates into the following assembly code:
RepeatLabel:
call print
byte "Enter a number greater than 100: ", 0
call readInt ; Function to read integer from user
cmp eax, 100 ; Assume readInt returns integer in EAX
jng RepeatLabel7.8.3 forever/endfor Loops
If while loops test for termination at the beginning of the loop and repeat/until/do/while loops check for termination at the end of the loop, the only place left to test for termination is in the middle of the loop. The C/C++ high-level for(;;) loop, combined with the break statement, provides this capability. The C/C++ infinite loop takes the following form:
for(;;)
{
Loop body
}There is no explicit termination condition. Unless otherwise provided, the for(;;) construct forms an infinite loop. A break statement usually handles loop termination. Consider the following C++ code that employs a for(;;) construct:
for(;;)
{
cin >> character;
if(character == '.') break;
cout << character;
}Converting a for(ever) loop to pure assembly language is easy. All you need is a label and a jmp instruction. The break statement in this example is also nothing more than a jmp instruction (or conditional jump). The pure assembly language version of the preceding code looks something like the following:
foreverLabel:
call getchar ; Assume it returns char in AL
cmp al, '.'
je ForIsDone
mov cl, al ; Pass char read from getchar to putchar
call putcchar ; Assume this prints the char in CL
jmp foreverLabel
ForIsDone:7.8.4 for Loops
The standard for loop is a special form of the while loop that repeats the loop body a specific number of times (this is known as a definite loop). In C/C++, the for loop takes the form
for(initialization_Stmt; termination_expression; inc_Stmt)
{
Statements
}which is equivalent to the following:
initialization_Stmt;
while(termination_expression)
{
Statements
inc_Stmt;
}Traditionally, programs use the for loop to process arrays and other objects accessed in sequential order. We normally initialize a loop-control variable with the initialization statement and then use the loop-control variable as an index into the array (or other data type). For example:
for(i = 0; i < 7; ++i)
{
printf("Array Element = %d \ n", SomeArray[i]);
}To convert this to pure assembly language, begin by translating the for loop into an equivalent while loop:
i = 0;
while(i < 7)
{
printf("Array Element = %d \ n", SomeArray[i]);
++i;
}Now, using the techniques from “while Loops” on page 433, translate the code into pure assembly language:
xor rbx, rbx ; Use RBX to hold loop index
WhileLp: cmp ebx, 7
jnl EndWhileLp
lea rcx, fmtStr ; fmtStr = "Array Element = %d", nl, 0
lea rdx, SomeArray
mov rdx, [rdx][rbx * 4] ; Assume SomeArray is 4-byte ints
call printf
inc rbx
jmp WhileLp;
EndWhileLp:7.8.5 The break and continue Statements
The C/C++ break and continue statements both translate into a single jmp instruction. The break instruction exits the loop that immediately contains the break statement; the continue statement restarts the loop that contains the continue statement.
To convert a break statement to pure assembly language, just emit a goto/jmp instruction that transfers control to the first statement following the end of the loop to exit. You can do this by placing a label after the loop body and jumping to that label. The following code fragments demonstrate this technique for the various loops.
// Breaking out of a FOR(;;) loop:
for(;;)
{
Stmts
// break;
goto BreakFromForever;
Stmts
}
BreakFromForever:
// Breaking out of a FOR loop:
for(initStmt; expr; incStmt)
{
Stmts
// break;
goto BrkFromFor;
Stmts
}
BrkFromFor:
// Breaking out of a WHILE loop:
while(expr)
{
Stmts
// break;
goto BrkFromWhile;
Stmts
}
BrkFromWhile:
// Breaking out of a REPEAT/UNTIL loop (DO/WHILE is similar):
repeat
Stmts
// break;
goto BrkFromRpt;
Stmts
until(expr);
BrkFromRpt:In pure assembly language, convert the appropriate control structures to assembly and replace the goto with a jmp instruction.
The continue statement is slightly more complex than the break statement. The implementation is still a single jmp instruction; however, the target label doesn’t wind up going in the same spot for each of the different loops. Figures 7-2, 7-3, 7-4, and 7-5 show where the continue statement transfers control for each of the loops.
Figure 7-2: continue destination for the for(;;) loop

Figure 7-3: continue destination and the while loop

Figure 7-4: continue destination and the for loop

Figure 7-5: continue destination and the repeat/until loop
The following code fragments demonstrate how to convert the continue statement into an appropriate jmp instruction for each of these loop types:
for(;;)/continue/endfor
; Conversion of FOREVER loop with continue
; to pure assembly:
for(;;)
{
Stmts
continue;
Stmts
}
; Converted code:
foreverLbl:
Stmts
; continue;
jmp foreverLbl
Stmts
jmp foreverLblwhile/continue/endwhile
; Conversion of WHILE loop with continue
; into pure assembly:
while(expr)
{
Stmts
continue;
Stmts
}
; Converted code:
whlLabel:
Code to evaluate expr
jcc EndOfWhile ; Skip loop on expr failure
Stmts
; continue;
jmp whlLabel ; Jump to start of loop on continue
Stmts
jmp whlLabel ; Repeat the code
EndOfWhile:for/continue/endfor
; Conversion for a FOR loop with continue
; into pure assembly:
for(initStmt; expr; incStmt)
{
Stmts
continue;
Stmts
}
; Converted code:
initStmt
ForLpLbl:
Code to evaluate expr
jcc EndOfFor ; Branch if expression fails
Stmts
; continue;
jmp ContFor ; Branch to incStmt on continue
Stmts
ContFor:
incStmt
jmp ForLpLbl
EndOfFor:repeat/continue/until
repeat
Stmts
continue;
Stmts
until(expr);
do
{
Stmts
continue;
Stmts
}while(!expr);
; Converted code:
RptLpLbl:
Stmts
; continue;
jmp ContRpt ; Continue branches to termination test
Stmts
ContRpt:
Code to test expr
jcc RptLpLbl ; Jumps if expression evaluates false7.8.6 Register Usage and Loops
Given that the x86-64 accesses registers more efficiently than memory locations, registers are the ideal spot to place loop-control variables (especially for small loops). However, registers are a limited resource; there are only 16 general-purpose registers (and some, such as RSP and RBP, are reserved for special purposes). Compared with memory, you cannot place much data in the registers, despite them being more efficient to use than memory.
Loops present a special challenge for registers. Registers are perfect for loop-control variables because they’re efficient to manipulate and can serve as indexes into arrays and other data structures (a common use for loop-control variables). However, the limited availability of registers often creates problems when using registers in this fashion. Consider the following code that will not work properly because it attempts to reuse a register (CX) that is already in use (leading to the corruption of the outer loop’s loop-control variable):
mov cx, 8
loop1:
mov cx, 4
loop2:
Stmts
dec cx
jnz loop2
dec cx
jnz loop1The intent here, of course, was to create a set of nested loops; that is, one loop inside another. The inner loop (loop2) should repeat four times for each of the eight executions of the outer loop (loop1). Unfortunately, both loops use the same register as a loop-control variable. Therefore, this will form an infinite loop. Because CX is always 0 upon encountering the second dec instruction, control will always transfer to the loop1 label (because decrementing 0 produces a nonzero result). The solution here is to save and restore the CX register or to use a different register in place of CX for the outer loop:
mov cx, 8
loop1:
push rcx
mov cx, 4
loop2:
Stmts
dec cx
jnz loop2;
pop rcx
dec cx
jnz loop1
or
mov dx,8
loop1:
mov cx, 4
loop2:
Stmts
dec cx
jnz loop2
dec dx
jnz loop1Register corruption is one of the primary sources of bugs in loops in assembly language programs, so always keep an eye out for this problem.
7.9 Loop Performance Improvements
Because loops are the primary source of performance problems within a program, they are the place to look when attempting to speed up your software. While a treatise on how to write efficient programs is beyond the scope of this chapter, you should be aware of the following concepts when designing loops in your programs. They’re all aimed at removing unnecessary instructions from your loops in order to reduce the time it takes to execute a single iteration of the loop.
7.9.1 Moving the Termination Condition to the End of a Loop
Consider the following flow graphs for the three types of loops presented earlier:
REPEAT/UNTIL loop:
Initialization code
Loop body
Test for termination
Code following the loop
WHILE loop:
Initialization code
Loop-termination test
Loop body
Jump back to test
Code following the loop
FOREVER/ENDFOR loop:
Initialization code
Loop body part one
Loop-termination test
Loop body part two
Jump back to Loop body part one
Code following the loopAs you can see, the repeat/until loop is the simplest of the bunch. This is reflected in the assembly language implementation of these loops. Consider the following repeat/until and while loops that are semantically identical:
; Example involving a WHILE loop:
mov esi, edi
sub esi, 20
; while(ESI <= EDI)
whileLp: cmp esi, edi
jnle endwhile
Stmts
inc esi
jmp whileLp
endwhile:
; Example involving a REPEAT/UNTIL loop:
mov esi, edi
sub esi, 20
repeatLp:
Stmts
inc esi
cmp esi, edi
jng repeatLpTesting for the termination condition at the end of the loop allows us to remove a jmp instruction from the loop, which can be significant if the loop is nested inside other loops. Given the definition of the loop, you can easily see that the loop will execute exactly 20 times, which suggests that the conversion to a repeat/until loop is trivial and always possible.
Unfortunately, it’s not always quite this easy. Consider the following C code:
while(esi <= edi)
{
Stmts
++esi;
}In this particular example, we haven’t the slightest idea what ESI contains upon entry into the loop. Therefore, we cannot assume that the loop body will execute at least once. So, we must test for loop termination before executing the body of the loop. The test can be placed at the end of the loop with the inclusion of a single jmp instruction:
jmp WhlTest
TopOfLoop:
Stmts
inc esi
WhlTest: cmp esi, edi
jle TopOfLoopAlthough the code is as long as the original while loop, the jmp instruction executes only once rather than on each repetition of the loop. However, the slight gain in efficiency is obtained via a slight loss in readability (so be sure to comment it). The second code sequence is closer to spaghetti code than the original implementation. Such is often the price of a small performance gain. Therefore, you should carefully analyze your code to ensure that the performance boost is worth the loss of clarity.
7.9.2 Executing the Loop Backward
Because of the nature of the flags on the x86-64, loops that repeat from some number down to (or up to) 0 are more efficient than loops that execute from 0 to another value. Compare the following C/C++ for loop and the comparable assembly language code:
for(j = 1; j <= 8; ++j)
{
Stmts
}
; Conversion to pure assembly (as well as using a
; REPEAT/UNTIL form):
mov j, 1
ForLp:
Stmts
inc j
cmp j, 8
jle ForLpNow consider another loop that also has eight iterations but runs its loop-control variable from 8 down to 1 rather than 1 up to 8, thereby saving a comparison on each repetition of the loop:
mov j, 8
LoopLbl:
Stmts
dec j
jnz LoopLblSaving the execution time of the cmp instruction on each iteration of the loop may result in faster code. Unfortunately, you cannot force all loops to run backward. However, with a little effort and some coercion, you should be able to write many for loops so that they operate backward.
The preceding example worked out well because the loop ran from 8 down to 1. The loop terminated when the loop-control variable became 0. What happens if you need to execute the loop when the loop-control variable goes to 0? For example, suppose that the preceding loop needed to range from 7 down to 0. As long as the lower bound is non-negative, you can substitute the jns instruction in place of the jnz instruction in the earlier code:
mov j, 7
LoopLbl:
Stmts
dec j
jns LoopLblThis loop will repeat eight times, with j taking on the values 7 to 0. When it decrements 0 to –1, it sets the sign flag and the loop terminates.
Keep in mind that some values may look positive but are actually negative. If the loop-control variable is a byte, values in the range 128 to 255 are negative in the two’s complement system. Therefore, initializing the loop-control variable with any 8-bit value in the range 129 to 255 (or, of course, 0) terminates the loop after a single execution. This can get you into trouble if you’re not careful.
7.9.3 Using Loop-Invariant Computations
A loop-invariant computation is a calculation that appears within a loop that always yields the same result. You needn’t do such computations inside the loop. You can compute them outside the loop and reference the value of the computations inside the loop. The following C code demonstrates an invariant computation:
for(i = 0; i < n; ++i)
{
k = (j - 2) + i
}Because j never changes throughout the execution of this loop, the subexpression j - 2 can be computed outside the loop:
jm2 = j - 2;
for(i = 0; i < n; ++i)
{
k = jm2 + i;
}Although we’ve eliminated a single instruction by computing the subexpression j - 2 outside the loop, there is still an invariant component to this calculation: adding j - 2 to i n times. Because this invariant component executes n times in the loop, we can translate the previous code to the following:
k = (j - 2) * n;
for(i = 0; i < n; ++i)
{
k = k + i;
}This translates to the following assembly code:
mov eax, j
sub eax, 2
imul eax, n
mov ecx, 0
lp: cmp ecx, n
jnl loopDone
add eax, ecx ; Single instruction implements loop body!
inc ecx
jmp lp
loopDone:
mov k, eaxFor this particular loop, you can actually compute the result without using a loop at all (a formula corresponds to the preceding iterative calculation). Still, this simple example demonstrates how to eliminate loop-invariant calculations from a loop.
7.9.4 Unraveling Loops
For small loops—those whose body is only a few statements—the overhead required to process a loop may constitute a significant percentage of the total processing time. For example, look at the following Pascal code and its associated x86-64 assembly language code:
for i := 3 downto 0 do A[i] := 0;
mov i, 3
lea rcx, A
LoopLbl:
mov ebx, i
mov [rcx][rbx * 4], 0
dec i
jns LoopLblFour instructions execute on each repetition of the loop. Only one instruction is doing the desired operation (moving a 0 into an element of A). The remaining three instructions control the loop. Therefore, it takes 16 instructions to do the operation logically required by 4.
While we could make many improvements to this loop based on the information presented thus far, consider carefully exactly what this loop is doing—it’s storing four 0s into A[0] through A[3]. A more efficient approach is to use four mov instructions to accomplish the same task. For example, if A is an array of double words, the following code initializes A much faster than the preceding code:
mov A[0], 0
mov A[4], 0
mov A[8], 0
mov A[12], 0Although this is a simple example, it shows the benefit of loop unraveling (also known as loop unrolling). If this simple loop appeared buried inside a set of nested loops, the 4:1 instruction reduction could possibly double the performance of that section of your program.
Of course, you cannot unravel all loops. Loops that execute a variable number of times are difficult to unravel because there is rarely a way to determine at assembly time the number of loop iterations. Therefore, unraveling a loop is a process best applied to loops that execute a known number of times, with the number of times known at assembly time.
Even if you repeat a loop a fixed number of iterations, it may not be a good candidate for loop unraveling. Loop unraveling produces impressive performance improvements when the number of instructions controlling the loop (and handling other overhead operations) represents a significant percentage of the total number of instructions in the loop. Had the previous loop contained 36 instructions in the body (exclusive of the four overhead instructions), the performance improvement would be, at best, only 10 percent (compared with the 300 to 400 percent it now enjoys).
Therefore, the costs of unraveling a loop—all the extra code that must be inserted into your program—quickly reach a point of diminishing returns as the body of the loop grows larger or as the number of iterations increases. Furthermore, entering that code into your program can become quite a chore. Therefore, loop unraveling is a technique best applied to small loops.
Note that the superscalar 80x86 chips (Pentium and later) have branch-prediction hardware and use other techniques to improve performance. Loop unrolling on such systems may actually slow the code because these processors are optimized to execute short loops. Whenever applying “improvements” to speed up your code, you should always measure the performance before and after to ensure there was sufficient gain to justify the change.
7.9.5 Using Induction Variables
Consider the following Pascal loop:
for i := 0 to 255 do csetVar[i] := [];Here the program is initializing each element of an array of character sets to the empty set. The straightforward code to achieve this is the following:
mov i, 0
lea rcx, csetVar
FLp:
; Compute the index into the array (assume that each
; element of a csetVar array contains 16 bytes).
mov ebx, i ; Zero-extends into RBX!
shl ebx, 4
; Set this element to the empty set (all 0 bits).
xor rax, rax
mov qword ptr [rcx][rbx], rax
mov qword ptr [rcx][rbx + 8], rax
inc i
cmp i, 256
jb FLp;Although unraveling this code will still improve performance, it will take 1024 instructions to accomplish this task, too many for all but the most time-critical applications. However, you can reduce the execution time of the body of the loop by using induction variables. An induction variable is one whose value depends entirely on the value of another variable.
In the preceding example, the index into the array csetVar tracks the loop-control variable (it’s always equal to the value of the loop-control variable times 16). Because i doesn’t appear anywhere else in the loop, there is no sense in performing the computations on i. Why not operate directly on the array index value? The following code demonstrates this technique:
xor rbx, rbx ; i * 16 in RBX
xor rax, rax ; Loop invariant
lea rcx, csetVar ; Base address of csetVar array
FLp:
mov qword ptr [rcx][rbx], rax
mov qword ptr [rcx][rbx + 8], rax
add ebx, 16
cmp ebx, 256 * 16
jb FLp
; mov ebx, 256 ; If you care to maintain same semantics as C codeThe induction that takes place in this example occurs when the code increments the loop-control variable (moved into EBX for efficiency) by 16 on each iteration of the loop rather than by 1. Multiplying the loop-control variable by 16 (and the final loop-termination constant value) allows the code to eliminate multiplying the loop-control variable by 16 on each iteration of the loop (that is, this allows us to remove the shl instruction from the previous code). Further, because this code no longer refers to the original loop-control variable (i), the code can maintain the loop-control variable strictly in the EBX register.
7.10 For More Information
Write Great Code, Volume 2, by this author (Second Edition, No Starch Press, 2020) provides a good discussion of the implementation of various HLL control structures in low-level assembly language. It also discusses optimizations such as induction, unrolling, strength reduction, and so on, that apply to optimizing loops.
7.11 Test Yourself
- What are the two typical mechanisms for obtaining the address of a label appearing in a program?
- What statement can you use to make all symbols global that appear within a procedure?
- What statement can you use to make all symbols local that appear within a procedure?
- What are the two forms of the indirect
jmpinstruction? - What is a state machine?
- What is the general rule for converting a branch to its opposite branch?
- What are the two exceptions to the rule for converting a branch to its opposite branch?
- What is a trampoline?
- What is the general syntax of the conditional move instruction?
- What is the advantage of a conditional move instruction over a conditional jump?
- What are some disadvantages of conditional moves?
- Explain the difference between short-circuit and complete Boolean evaluation.
- Convert the following
ifstatements to assembly language sequences by using complete Boolean evaluation (assume all variables are unsigned 32-bit integer values):if(x == y || z > t) { Do something } if(x != y && z < t) { THEN statements } else { ELSE statements } - Convert the preceding statements to assembly language by using short-circuit Boolean evaluation (assume all variables are signed 16-bit integer values).
- Convert the following
switchstatements to assembly language (assume all variables are unsigned 32-bit integers):switch(s) { case 0: case 0 code break; case 1: case 1 code break; case 2: case 2 code break; case 3: case 3 code break; } switch(t) { case 2: case 0 code break; case 4: case 4 code break; case 5: case 5 code break; case 6: case 6 code break; default: Default code } switch(u) { case 10: case 10 code break; case 11: case 11 code break; case 12: case 12 code break; case 25: case 25 code break; case 26: case 26 code break; case 27: case 27 code break; default: Default code } - Convert the following
whileloops to assembly code (assume all variables are signed 32-bit integers):while(i < j) { Code for loop body } while(i < j && k != 0) { Code for loop body, part a if(m == 5) continue; Code for loop body, part b if(n < 6) break; Code for loop body, part c } do { Code for loop body } while(i != j); do { Code for loop body, part a if(m != 5) continue; Code for loop body, part b if(n == 6) break; Code for loop body, part c } while(i < j && k > j); for(int i = 0; i < 10; ++i) { Code for loop body }