14
The String Instructions

A string is a collection of values stored in contiguous memory locations. The x86-64 CPUs can process four types of strings: byte strings, word strings, double-word strings, and quad-word strings.
The x86-64 microprocessor family supports several instructions specifically designed to cope with strings. They can move strings, compare strings, search for a specific value within a string, initialize a string to a fixed value, and do other primitive operations on strings. The x86-64’s string instructions are also useful for assigning and comparing arrays, tables, and records, and they may speed up your array-manipulation code considerably. This chapter explores various uses of the string instructions.
14.1 The x86-64 String Instructions
All members of the x86-64 family support five string instructions: movsx, cmpsx, scasx, lodsx, and stosx.1 (x = b, w, d, or q for byte, word, double word, or quad word, respectively; this book generally drops the x suffix when talking about these string instructions in a general sense.) Moving, comparing, scanning, loading, and storing are the primitives on which you can build most other string operations.
The string instructions operate on blocks (contiguous linear arrays) of memory. For example, the movs instruction moves a sequence of bytes from one memory location to another, the cmps instruction compares two blocks of memory, and the scas instruction scans a block of memory for a particular value. The source and destination blocks (and any other values an instruction needs) are not provided as explicit operands, however. Instead, the string instructions use specific registers as operands:
- RSI (source index) register
- RDI (destination index) register
- RCX (count) register
- AL, AX, EAX, and RAX registers
- The direction flag in the FLAGS register
For example, the movs (move string) instruction copies RCX elements from the source address specified by RSI to the destination address specified by RDI. Likewise, the cmps instruction compares the string pointed at by RSI, of length RCX, to the string pointed at by RDI.
The sections that follow describe how to use these five instructions, starting with a prefix that makes the instructions do what you’d expect: repeat their operation for each value in the string pointed to by RSI.2
14.1.1 The rep, repe, repz, and the repnz and repne Prefixes
By themselves, the string instructions do not operate on strings of data. For example, the movs instruction will only copy a single byte, word, double word, or quad word. The repeat prefixes tell the x86-64 to do a multi-byte string operation—specifically, to repeat a string operation up to RCX times.3
The syntax for the string instructions with repeat prefixes is as follows:
rep prefix:
rep movsx (x is b, w, d, or q)
rep stosx
repe prefix: (Note: repz is a synonym for repe)
repe cmpsx
repe scasx
repne prefix: (Note: repnz is a synonym for repne)
repne cmpsx
repne scasxYou don’t normally use the repeat prefixes with the lods instruction.
The rep prefix tells the CPU to “repeat this operation the number of times specified by the RCX register.” The repe prefix says to “repeat this operation while the comparison is equal, or up to the number of times specified by RCX (whichever condition fails first).” The repne prefix’s action is “repeat this operation while the comparison is not equal, or up to the number of times specified by RCX.” As it turns out, you’ll use repe for most character string comparisons; repne is used mainly with the scasx instructions to locate a specific character within a string (such as a zero-terminating byte).
You can use repeat prefixes to process entire strings with a single instruction. You can use the string instructions, without the repeat prefix, as string primitive operations to synthesize more powerful string operations.
14.1.2 The Direction Flag
The direction flag in the FLAGS register controls how the CPU processes strings. If the direction flag is clear, the CPU increments RSI and RDI after operating on each string element. For example, executing movs will move the byte, word, double word, or quad word at RSI to RDI and then increment RSI and RDI by 1, 2, 4, or 8 (respectively). When specifying the rep prefix before this instruction, the CPU increments RSI and RDI for each element in the string (the count in RCX specifies the number of elements). At completion, the RSI and RDI registers will be pointing at the first item beyond the strings.
If the direction flag is set, the x86-64 decrements RSI and RDI after it processes each string element (again, RCX specifies the number of string elements for a repeated string operation). Afterward, the RSI and RDI registers will be pointing at the first byte, word, or double word before the strings.
You can change the direction flag’s value by using the cld (clear direction flag) and std (set direction flag) instructions.
The Microsoft ABI requires that the direction flag be clear upon entry into a (Microsoft ABI–compliant) procedure. Therefore, if you set the direction flag within a procedure, you should always clear that flag when you are finished using it (and especially before calling any other code or returning from the procedure).
14.1.3 The movs Instruction
The movs instruction uses the following syntax:
movsb
movsw
movsd
movsq
rep movsb
rep movsw
rep movsd
rep movsqThe movsb (move string, bytes) instruction fetches the byte at address RSI, stores it at address RDI, and then increments or decrements the RSI and RDI registers by 1. If the rep prefix is present, the CPU checks RCX to see whether it contains 0. If not, it moves the byte from RSI to RDI and decrements the RCX register. This process repeats until RCX becomes 0. If RCX contains 0 upon initial execution, the movsb instruction will not copy any data bytes.
The movsw (move string, words) instruction fetches the word at address RSI, stores it at address RDI, and then increments or decrements RSI and RDI by 2. If there is a rep prefix, the CPU repeats this procedure RCX times.
The movsd instruction operates in a similar fashion on double words. It increments or decrements RSI and RDI by 4 after each data movement.
Finally, the movsq instruction does the same thing on quad words. It increments or decrements RSI and RDI by 8 after each data movement.
For example, this code segment copies 384 bytes from CharArray1 to CharArray2:
CharArray1 byte 384 dup (?)
CharArray2 byte 384 dup (?)
.
.
.
cld
lea rsi, CharArray1
lea rdi, CharArray2
mov rcx, lengthof(CharArray1) ; = 384
rep movsbIf you substitute movsw for movsb, the preceding code will move 384 words (768 bytes) rather than 384 bytes:
WordArray1 word 384 dup (?)
WordArray2 word 384 dup (?)
.
.
.
cld
lea rsi, WordArray1
lea rdi, WordArray2
mov rcx, lengthof(WordArray1) ; = 384
rep movswRemember, the RCX register contains the element count, not the byte count; fortunately, the MASM lengthof operator returns the number of array elements (words), not the number of bytes.
If you’ve set the direction flag before executing a movsq, movsb, movsw, or movsd instruction, the CPU decrements the RSI and RDI registers after moving each string element. This means that the RSI and RDI registers must point at the last element of their respective strings before executing a movsb, movsw, movsd, or movsq instruction. For example:
CharArray1 byte 384 dup (?)
CharArray2 byte 384 dup (?)
.
.
.
std
lea rsi, CharArray1[lengthof(CharArray1) - 1]
lea rdi, CharArray2[lengthof(CharArray1) - 1]
mov rcx, lengthof(CharArray1);
rep movsb
cldAlthough sometimes processing a string from tail to head is useful (see “Comparing Extended-Precision Integers” on page 834), generally you’ll process strings in the forward direction. For one class of string operations, being able to process strings in both directions is mandatory: moving strings when the source and destination blocks overlap. Consider what happens in the following code:
CharArray1 byte ?
CharArray2 byte 384 dup (?)
.
.
.
cld
lea rsi, CharArray1
lea rdi, CharArray2
mov rcx, lengthof(CharArray2);
rep movsbThis sequence of instructions treats CharArray1 and CharArray2 as a pair of 384-byte strings. However, the last 383 bytes in the CharArray1 array overlap the first 383 bytes in the CharArray2 array. Let’s trace the operation of this code byte by byte.
When the CPU executes the movsb instruction, it does the following:
- Copies the byte at RSI (
CharArray1) to the byte pointed at by RDI (CharArray2). - Increments RSI and RDI, and decrements RCX by 1. Now the RSI register points at
CharArray1 + 1(which is the address ofCharArray2), and the RDI register points atCharArray2 + 1. - Copies the byte pointed at by RSI to the byte pointed at by RDI. However, this is the byte originally copied from location
CharArray1. So, themovsbinstruction copies the value originally in locationCharArray1to both locationsCharArray2andCharArray2 + 1. - Again increments RSI and RDI, and decrements RCX.
- Copies the byte from location
CharArray1 + 2(CharArray2 + 1) to locationCharArray2 + 2. Once again, this is the value that originally appeared in locationCharArray1.
Each repetition of the loop copies the next element in CharArray1 to the next available location in the CharArray2 array. Pictorially, it looks something like Figure 14-1. The result is that the movsb instruction replicates X throughout the string.
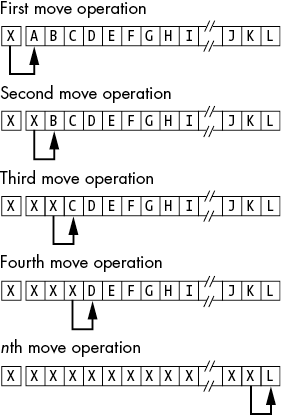
Figure 14-1: Copying data between two overlapping arrays (forward direction)
If you really want to move one array into another when they overlap like this, you should move each element of the source string to the destination string, starting at the end of the two strings, as shown in Figure 14-2.
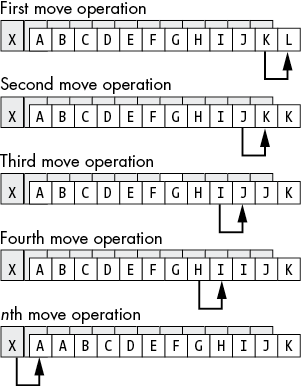
Figure 14-2: Using a backward copy to copy data in overlapping arrays
Setting the direction flag and pointing RSI and RDI at the end of the strings will allow you to (correctly) move one string to another when the two strings overlap and the source string begins at a lower address than the destination string. If the two strings overlap and the source string begins at a higher address than the destination string, clear the direction flag and point RSI and RDI at the beginning of the two strings.
If the two strings do not overlap, you can use either technique to move the strings around in memory. Generally, operating with the direction flag clear is the easiest.
You shouldn’t use the movsx instruction to fill an array with a single byte, word, double-word, or quad-word value. Another string instruction, stos, is much better for this purpose.
If you are moving a large number of bytes from one array to another, the copy operation will be faster if you can use the movsq instruction rather than the movsb instruction. If the number of bytes you wish to move is an even multiple of 8, this is a trivial change; just divide the number of bytes to copy by 8, load this value into RCX, and then use the movsq instruction. If the number of bytes is not evenly divisible by 8, you can use the movsq instruction to copy all but the last 1, 2, . . . , 7 bytes of the array (that is, the remainder after you divide the byte count by 8). For example, if you want to efficiently move 4099 bytes, you can do so with the following instruction sequence:
lea rsi, Source
lea rdi, Destination
mov rcx, 512 ; Copy 512 qwords = 4096 bytes
rep movsq
movsw ; Copy bytes 4097 and 4098
movsb ; Copy the last byteUsing this technique to copy data never requires more than four movsx instructions because you can copy 1, . . . , 7 bytes with no more than one (each) of the movsb, movsw, and movsd instructions. The preceding scheme is most efficient if the two arrays are aligned on quad-word boundaries. If not, you might want to move the movsb, movsw, or movsd instruction (or all three) before or after the movsq instruction so that movsq works with quad-word–aligned data.
If you do not know the size of the block you are copying until the program executes, you can still use code like the following to improve the performance of a block move of bytes:
lea rsi, Source
lea rdi, Destination
mov rcx, Length
shr rcx, 3 ; Divide by 8
jz lessThan8 ; Execute movsq only if 8 or more bytes
rep movsq ; Copy the qwords
lessThan8:
mov rcx, Length
and rcx, 111b ; Compute (Length mod 8)
jz divisibleBy8 ; Execute movsb only if # of bytes/8 <> 0
rep movsb ; Copy the remaining 1 to 7 bytes
divisibleBy8: On many computer systems, the movsq instruction provides about the fastest way to copy bulk data from one location to another. While there are, arguably, faster ways to copy data on certain CPUs, ultimately the memory bus performance is the limiting factor, and the CPUs are generally much faster than the memory bus. Therefore, unless you have a special system, writing fancy code to improve memory-to-memory transfers is probably a waste of time.
Also, Intel has improved the performance of the movsx instructions on later processors so that movsb operates as efficiently as movsw, movsd, and movsq when copying the same number of bytes. On these later processors, it may be more efficient to use movsb to copy the specified number of bytes rather than go through all the complexity outlined previously.
The bottom line is this: if the speed of a block move matters to you, try it several different ways and pick the fastest (or the simplest, if they all run the same speed, which is likely).
14.1.4 The cmps Instruction
The cmps instruction compares two strings. The CPU compares the value referenced by RDI to the value pointed at by RSI. RCX contains the number of elements in the source string when using the repe or repne prefix to compare entire strings. Like the movs instruction, MASM allows several forms of this instruction:
cmpsb
cmpsw
cmpsd
cmpsq
repe cmpsb
repe cmpsw
repe cmpsd
repe cmpsq
repne cmpsb
repne cmpsw
repne cmpsd
repne cmpsqWithout a repeat prefix, the cmps instruction subtracts the value at location RDI from the value at RSI and updates the flags according to the result (which it discards). After comparing the two locations, cmps increments or decrements the RSI and RDI registers by 1, 2, 4, or 8 (for cmpsb, cmpsw, cmpsd, and cmpsq, respectively). cmps increments the RSI and RDI registers if the direction flag is clear and decrements them otherwise.
Remember, the value in the RCX register determines the number of elements to process, not the number of bytes. Therefore, when using cmpsw, RCX specifies the number of words to compare. Likewise, for cmpsd and cmpsq, RCX contains the number of double and quad words to process.
The repe prefix compares successive elements in a string as long as they are equal and RCX is greater than 0. The repne prefix does the same as long the elements are not equal.
After the execution of repne cmps, either the RCX register is 0 (in which case the two strings are totally different), or the RCX contains the number of elements compared in the two strings until a match is found. While this form of the cmps instruction isn’t particularly useful for comparing strings, it is useful for locating the first pair of matching items in a couple of byte, word, or double-word arrays.
14.1.4.1 Comparing Character Strings
Character strings are usually compared using lexicographical ordering, the standard alphabetical ordering you’ve grown up with. We compare corresponding elements until encountering a character that doesn’t match or the end of the shorter string. If a pair of corresponding characters does not match, compare the two strings based on that single character. If the two strings match up to the length of the shorter string, compare their length. The two strings are equal if and only if their lengths are equal and each corresponding pair of characters in the two strings is identical. The length of a string affects the comparison only if the two strings are identical up to the length of the shorter string. For example, Zebra is less than Zebras because it is the shorter of the two strings; however, Zebra is greater than AAAAAAAAAAH! even though Zebra is shorter.
For (ASCII) character strings, use the cmpsb instruction in the following manner:
- Clear the direction flag.
- Load the RCX register with the length of the smaller string.
- Point the RSI and RDI registers at the first characters in the two strings you want to compare.
- Use the
repeprefix with thecmpsbinstruction to compare the strings on a byte-by-byte basis. - If the two strings are equal, compare their lengths.
The following code compares a couple of character strings:
cld
mov rsi, AdrsStr1
mov rdi, AdrsStr2
mov rcx, LengthSrc
cmp rcx, LengthDest
jbe srcIsShorter ; Put the length of the
; shorter string in RCX
mov rcx, LengthDest
srcIsShorter:
repe cmpsb
jnz notEq ; If equal to the length of the
; shorter string, cmp lengths
mov rcx, LengthSrc
cmp rcx, LengthDest
notEq: If you’re using bytes to hold the string lengths, you should adjust this code appropriately (that is, use a movzx instruction to load the lengths into RCX).
14.1.4.2 Comparing Extended-Precision Integers
You can also use the cmps instruction to compare multi-word integer values (that is, extended-precision integer values). Because of the setup required for a string comparison, this isn’t practical for integer values less than six or eight double words in length, but for large integer values, it’s excellent.
Unlike with character strings, we cannot compare integer strings by using lexicographical ordering. When comparing strings, we compare the characters from the least significant byte to the most significant byte. When comparing integers, we must compare the values from the most significant byte, word, or double word down to the least significant. So, to compare two 32-byte (256-bit) integer values, use the following code:
std
lea rsi, SourceInteger[3 * 8]
lea rdi, DestInteger[3 * 8]
mov rcx, 4
repe cmpsq
cldThis code compares the integers from their most significant qword down to the least significant qword. The cmpsq instruction finishes when the two values are unequal or upon decrementing RCX to 0 (implying that the two values are equal). Once again, the flags provide the result of the comparison.
14.1.5 The scas Instruction
The scas (scan string) instruction is used to search for a particular element within a string—for example, to quickly scan for a 0 throughout another string.
Unlike the movs and cmps instructions, scas requires only a destination string (pointed at by RDI). The source operand is the value in the AL (scasb), AX (scasw), EAX (scasd), or RAX (scasq) register. The scas instruction compares the value in the accumulator (AL, AX, EAX, or RAX) against the value pointed at by RDI and then increments (or decrements) RDI by 1, 2, 4, or 8. The CPU sets the flags according to the result of the comparison.
The scas instructions take the following forms:
scasb
scasw
scasd
scasq
repe scasb
repe scasw
repe scasd
repe scasq
repne scasb
repne scasw
repne scasd
repne scasqWith the repe prefix, scas scans the string, searching for an element that does not match the value in the accumulator. When using the repne prefix, scas scans the string, searching for the first element that is equal to the value in the accumulator. This is counterintuitive, because repe scas actually scans through the string while the value in the accumulator is equal to the string operand, and repne scas scans through the string while the accumulator is not equal to the string operand.
Like the cmps and movs instructions, the value in the RCX register specifies the number of elements, not bytes, to process when using a repeat prefix.
14.1.6 The stos Instruction
The stos instruction stores the value in the accumulator at the location specified by RDI. After storing the value, the CPU increments or decrements RDI depending on the state of the direction flag. Although the stos instruction has many uses, its primary use is to initialize arrays and strings to a constant value. For example, if you have a 256-byte array that you want to clear out with 0s, use the following code:
cld
lea rdi, DestArray
mov rcx, 32 ; 32 quad words = 256 bytes
xor rax, rax ; Zero out RAX
rep stosqThis code writes 32 quad words rather than 256 bytes because a single stosq operation is faster (on some older CPUs) than four stosb operations.
The stos instructions take eight forms:
stosb
stosw
stosd
stosq
rep stosb
rep stosw
rep stosd
rep stosqThe stosb instruction stores the value in the AL register into the specified memory location(s), stosw stores the AX register into the specified memory location(s), stosd stores EAX into the specified location(s), and stosq stores RAX into the specified location(s). With the rep prefix, this process repeats the number of times specified by the RCX register.
If you need to initialize an array with elements that have different values, you cannot (easily) use stos.
14.1.7 The lods Instruction
The lods instruction copies the byte, word, double word, or quad word pointed at by RSI into the AL, AX, EAX, or RAX register, after which it increments or decrements the RSI register by 1, 2, 4, or 8. Use lods to fetch bytes (lodsb), words (lodsw), double words (lodsd), or quad words (lodsq) from memory for further processing.
Like stos, the lods instructions take eight forms:
lodsb
lodsw
lodsd
lodsq
rep lodsb
rep lodsw
rep lodsd
rep lodsqYou will probably never use a repeat prefix with this instruction, because the accumulator register will be overwritten each time lods repeats. At the end of the repeat operation, the accumulator will contain the last value read from memory.4
14.1.8 Building Complex String Functions from lods and stos
You can use the lods and stos instructions to generate any particular string operation. For example, suppose you want a string operation that converts all the uppercase characters in a string to lowercase. You could use the following code:
mov rsi, StringAddress ; Load string address into RSI
mov rdi, rsi ; Also point RDI here
mov rcx, stringLength ; Presumably, this was precomputed
jrcxz skipUC ; Don't do anything if length is 0
rpt:
lodsb ; Get the next character in the string
cmp al, 'A'
jb notUpper
cmp al, 'Z'
ja notUpper
or al, 20h ; Convert to lowercase
notUpper:
stosb ; Store converted char into string
dec rcx
jnz rpt ; Zero flag is set when RCX is 0
skipUC:The rpt loop fetches the byte at the location specified by RSI, tests whether it is an uppercase character, converts it to lowercase if it is (leaving it unchanged if it is not), stores the resulting character at the location specified by RDI, and then repeats this process the number of times specified by the value in RCX.
Because the lods and stos instructions use the accumulator as an intermediary location, you can use any accumulator operation to quickly manipulate string elements. This could be something as simple as a toLower (or toUpper) function or as complex as data encryption. You might even use this instruction sequence to compute a hash, checksum, or CRC value while moving data from one string to another. Any operation you would do on a string on a character-by-character basis while moving the string data around is a candidate.
14.2 Performance of the x86-64 String Instructions
In the early x86-64 processors, the string instructions provided the most efficient way to manipulate strings and blocks of data. However, these instructions are not part of Intel’s RISC Core instruction set and can be slower (though more compact) than if you did the same operations with discrete instructions. Intel has optimized movs and stos on later processors so that they operate as rapidly as possible, but the other string instructions can be fairly slow.
As always, it’s a good idea to implement performance-critical algorithms by using different algorithms (with and without the string instructions) and comparing their performance to determine which solution to use. Because the string instructions run at different speeds relative to other instructions depending on which processor you’re using, try your experiments on the processors where you expect your code to run.
14.3 SIMD String Instructions
The SSE4.2 instruction set extensions include four powerful instructions for manipulating character strings. These instructions were first introduced in 2008, so some computers in use today still might not support them. Always use cpuid to determine if these instructions are available before attempting to use them in wide-distribution commercial applications (see “Using cpuid to Differentiate Instruction Sets” in Chapter 11).
The four SSE4.2 instructions that process text and string fragments are as follows:
PCMPESTRIPacked compare explicit-length strings, return indexPCMPESTRMPacked compare explicit-length strings, return maskPCMPISTRIPacked compare implicit-length strings, return indexPCMPISTRMPacked compare implicit-length strings, return mask
Implicit-length strings use a sentinel (trailing) byte to mark the end of the string, specifically, a zero-terminating byte (or word, in the case of Unicode characters). Explicit-length strings are those for which you supply a string length.
Instructions that produce an index return the index of the first (or last) matching occurrence within the source string. Instructions that return a bit mask return an array of 0 or (all) 1 bits that mark each occurrence of the match within the two input strings.
The packed compare string instructions are among the most complex in the x86-64 instruction set. The syntax for these instructions is
pcmpXstrY xmmsrc1, xmmsrc2/memsrc2, imm8
vpcmpXstrY xmmsrc1, xmmsrc2/memsrc2, imm8where X is E or I, and Y is I or M. Both forms use 128-bit operands (no 256-bit YMM registers for the v-prefixed form in this case), and, unlike most SSE instructions, the (v)pcmpXstrY instructions allow memory operands that are not aligned on a 16-byte boundary (they would be nearly useless for their intended operation if they required 16-byte-aligned memory operands).
The (v)pcmpXstrY instructions compare corresponding bytes or words in a pair of XMM registers, combine the results of the individual comparisons into a vector (bit mask), and return the results for all the comparisons. The imm8 operand controls various comparison attributes as described in “Type of Comparison” on the following page.
14.3.1 Packed Compare Operand Sizes
Bits 0 and 1 of the immediate operand specify the size and type of the string elements. The elements can be bytes or words, or they can be treated as unsigned or signed values for the comparison (see Table 14-1).
Bit 0 specifies word (Unicode) or byte (ASCII) operands. Bit 1 specifies whether the operands are signed or unsigned. Generally, for character strings, you use unsigned comparisons. However, in certain situations (or when processing strings of integers rather than characters), you may want to specify signed comparisons.
Table 14-1: Packed Compare imm8 Bits 0 and 1
| Bit(s) | Bit value | Meaning |
| 0–1 | 00 | Both source operands contain 16 unsigned bytes. |
| 01 | Both source operands contain 8 unsigned words. | |
| 10 | Both source operands contain 16 signed bytes. | |
| 11 | Both source operands contain 8 signed words. |
14.3.2 Type of Comparison
Bits 2 and 3 of the immediate operand specify how the instruction will compare the two strings. There are four comparison types, which test characters from one string against the set of characters in the second, test characters from one string against a range of characters, do a straight string comparison, or search for a substring within another string (see Table 14-2).
Table 14-2: Packed Compare imm8 Bits 2 and 3
| Bit(s) | Bit value | Meaning |
| 2–3 | 00 | Equal any: compares each character in the second source string against a set of characters appearing in the first source operand. |
| 01 | Ranges: compares each value in the second source operand against a set of ranges specified by the first source operand. | |
| 10 | Equal each: compares each corresponding element for equality (character-by-character comparison of the two operands). | |
| 11 | Equal ordered: searches for the substring specified by the first operand within the string specified by the second operand. |
Bits 2 to 3 specify the type of comparison to perform (the aggregate operation in Intel terminology). Equal each (10b) is probably the easiest comparison to understand. The packed compare instruction will compare each corresponding character in the string (up to the length of the string—more on that later) and set a Boolean flag for the result of the comparison of each byte or word in the string, as shown in Figure 14-3. This is comparable to the operation of the C/C++ memcmp() or strcmp() functions.
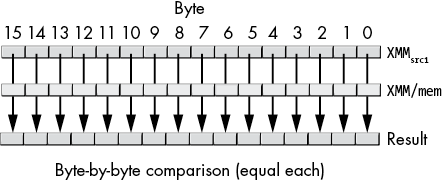
Figure 14-3: Equal each aggregate comparison operation
The equal any comparison compares each byte in the second source operand to see whether it is any of the characters found in the first source operand (XMMsrc2/memsrc2). For example, if XMMsrc1 contains the string abcdefABCDEF (and four 0 bytes), and XMMsrc2/memsrc2 contains 12AF89C0, the resulting comparison would yield 00101100b (1s in the character positions corresponding to the A, F, and C characters). Also note that the first character (1) maps to bit 0, and the A and F characters map to bits 2 and 3. This is similar to the strspn() and strcspn() functions in the C Standard Library.
The equal ordered comparison searches for each occurrence of the string in XMMsrc1 that can be found in the XMMsrc2/memsrc2 operand. For example, if the XMMsrc2/memsrc2 operand contains the string never need shine and the XMMsrc1 operand has the string ne (padded with 0s), then the equal ordered comparison produces the vector 0100000001000001b. This is similar to the strstr() function in the C Standard Library.
The ranges comparison aggregate operation breaks the entries in the XMMsrc1 operand into pairs (at even and odd indexes in the register). The first element (byte or word) specifies a lower bound, and the second entry specifies an upper bound. The XMMsrc1 register supports up to eight byte ranges or four word ranges (if you need fewer ranges, pad the remaining pairs with 0s). This aggregate operation compares each character in the XMMsrc2/memsrc2 operand against each of these ranges and stores true in the resultant vector if the character is within one of the specified ranges (inclusive) and false if it is outside all of these ranges.
14.3.3 Result Polarity
Bits 4 and 5 of the immediate operand specify the result polarity (see Table 14-3). This chapter will fully discuss the meaning of these bits in a moment (some additional commentary is necessary).
Table 14-3: Packed Compare imm8 Bits 4 and 5
| Bit(s) | Bit value | Meaning |
| 4–5 | 00 | Positive polarity |
| 01 | Negative polarity | |
| 10 | Positive masked | |
| 11 | Negative masked |
14.3.4 Output Processing
Bit 6 of the immediate operand specifies the instruction result (see Table 14-4). The packed compare instructions do not use bit 7; it should always be 0.
Table 14-4: Packed Compare imm8 Bit 6 (and 7)
| Bit(s) | Bit value | Meaning |
| 6 | 0 | (v)pcomXstri only, the index returned in ECX is the first result.(v)pcomXstrm only, the mask appears in the LO bits of XMM0 with zero extension to 128 bits. |
| 1 | (v)pcomXstri only, the index returned in ECX is the last result.(v)pcomXstrm only, expand the bit mask into a byte or word mask. |
|
| 7 | 0 | This bit is reserved and should always be 0. |
The (v)pcmpestrm and (v)pcmpistrm instructions produce a bit-mask result and store it into the XMM0 register (this is fixed—the CPU does not determine this by the operands to these instructions). If bit 6 of the imm8 operand contains a 0, these two instructions pack this bit mask into 8 or 16 bits and store them into the LO 8 (or 16) bits of XMM0, zero-extending that value through the upper bits of XMM0. If imm8 bit 6 contains a 1, these instructions will store the bit mask (all 1 bits per byte or word) throughout the XMM0 register.5
The (v)pcmpestri and (v)pcmpistri instructions produce an index result and return this value in the ECX register.6 If bit 6 of the imm8 operand contains a 0, these two instructions return the index of the LO set bit in the result bit mask (that is, the first matching comparison). If bit 6 of the imm8 operand is 1, these instructions return the index of the highest-order set bit in the resultant bit mask (that is, the last matching comparison). If there are no set bits in the result bit mask, these instructions return 16 (for byte comparisons) or 8 (for word comparisons) in the ECX register. Although these instructions internally generate a bit mask result in order to calculate the index, they do not overwrite the XMM0 register (as do the (v)pcmpestrm and (v)pcmpistrm instructions).
14.3.5 Packed String Compare Lengths
The (v)pcmpXstrY instructions have a 16-byte (XMM register size) comparison limit. This is true even on AVX processors with 32-byte YMM registers. To compare larger strings requires executing multiple (v)pcmpXstrY instructions.
The (v)pcmpistri and (v)pcmpistrm instructions use an implicit string length. The strings appear in the XMM registers or memory with the first character (if any) appearing in the LO byte followed by the remaining characters in the string. The strings end with a zero-terminating byte or word. If there are more than 16 characters (if byte strings, or 8 characters if word strings), then the register (or 128-bit memory) size delimits the string.
The (v)pcmpestri and (v)pcmpestrm instructions use explicitly supplied string lengths. The RAX and EAX registers specify the string length for the string appearing in XMMsrc1, and the RDX and EDX registers specify the string length for the string appearing in XMMsrc2/memsrc2. If the string length is greater than 16 (for byte strings) or 8 (for word strings), the instruction saturates the length at 16 or 8. Also, the (v)pcmpestri and (v)pcmpestrm instructions take the absolute value of the length, so –1 to –16 is equivalent to 1 to 16.
The reason the explicit-length instructions saturate the length to 16 (or 8) is to allow a program to process larger strings in a loop. By processing 16 bytes (or 8 words) at a time in a loop and decrementing the overall string length (from some large value down to 0), the packed string operations will operate on 16 or 8 characters per loop iteration until the very last loop iteration. At that point, the instructions will process the remaining (total length mod 16 or 8) characters in the string.
The reason the explicit-length instructions take the absolute value of the length is to allow code that processes large strings to either decrement the loop counter (from a large positive value) to 0 or increment the loop counter (from a negative value) toward 0, whichever is more convenient for the program.
Whenever the length (implicit or explicit) is less than 16 (for bytes) or 8 (for words), certain characters in the XMM register (or 128-bit memory location) will be invalid. Specifically, every character after the zero-terminating character (for implicit-length strings) or beyond the count in RAX and EAX or RDX and EDX will be invalid. Regardless of the presence of invalid characters, the packed compare instructions still produce an intermediate bit vector result by comparing all characters in the string.
Because the string lengths of the two input strings (in XMMsrc1 and XMMsrc2/memsrc2) are not necessarily equal, there are four possible situations: src1 and src2 are both invalid, exactly one of the two source operands is invalid (and the other is valid, so there are two cases here), or both are valid. Depending on which operands are valid or invalid, the packed compare instructions may force the result to true or false. Table 14-5 lists how these instructions force results, based on the type of comparison (aggregate operation) specified by the imm8 operand.
Table 14-5: Comparison Result When Source 1 and Source 2 Are Valid or Invalid
| Src1 | Src2 | Equal any | Ranges | Equal each | Equal ordered |
| Invalid | Invalid | Force false | Force false | Force true | Force true |
| Invalid | Valid | Force false | Force false | Force false | Force true |
| Valid | Invalid | Force false | Force false | Force false | Force false |
| Valid | Valid | Result | Result | Result | Result |
To understand the entries in this table, you must consider each comparison type individually.
The equal any comparison checks whether each character appearing in src2 appears anywhere in the set of characters specified by src1. If a character in src1 is invalid, that means the instructions are comparing against a character that is not in the set; in this situation, you want to return false (regardless of src2’s validity). If src1 is valid but src2 is invalid, you’re at (or beyond) the end of the string; that’s not a valid comparison, so equal any also forces a false result in this situation.
The ranges comparison is also (in a sense) comparing a source string (src2) against a set of characters (specified by the ranges in src1). Therefore, the packed compare instructions force false if either (or both) operands are invalid for the same reasons as equal any comparisons.
The equal each comparison is the traditional string comparison operation, comparing the string in src2 to the string in src1. If the corresponding character in both strings is invalid, you’ve moved beyond the end of both strings. The packed compare instructions force the result to true in this situation because these instructions are, effectively, comparing empty strings at this point (and empty strings are equal). If a character in one string is valid but the corresponding character in the other string is invalid, you’re comparing actual characters against an empty string, which is always not equal; hence, the packed string comparison instructions force a false result.
The equal ordered operation searches for the substring XMMsrc1 within the larger string XMMsrc2/memsrc2. If you’ve gone beyond the end of both strings, you’re comparing empty strings (and one empty string is always a substring of another empty string), so the packed comparison instructions return a true result. If you’ve reached the end of the string in src1 (the substring to search for), the result is true even if there are more characters in src2; hence, the packed comparisons return true in this situation. However, if you’ve reached the end of the src2 string but not the end of the src1 (substring) string, there is no way that equal ordered will return true, so the packed comparison instructions force a false in this situation.
If the polarity bits (bits 4 to 5 of imm8) contain 00b or 10b, the polarity bits do not affect the comparison operation. If the polarity bits are 01b, the packed string comparison instructions invert all the bits in the temporary bit map result before copying the data to XMM0 ((v)pcmpistrm and (v)pcmpestrm) or calculating the index ((v)pcmpestri and (v)pcmpistri). If the polarity setting is 11b, the packed string comparison instructions invert the resultant bit if and only if the corresponding src2 character is valid.
14.3.6 Packed String Comparison Results
The last thing to note about the packed string comparison instructions is how they affect the CPU flags. These instructions are unusual among the SSE/AVX instructions insofar as they affect the condition codes. However, they do not affect the condition codes in standard ways (for example, you cannot use the carry and zero flags to test for string less than or greater than, as you can with the cmps instructions). Instead, these instructions overload the meanings of the carry, zero, sign, and overflow flags; furthermore, each instruction defines the meaning of these flags independently.
All eight instructions—(v)pcmpestri, (v)pcmpistri, (v)pcmpestrm, and (v)pcmpistrm—clear the carry flag if all of the bits in the (internal) result bit map are 0 (no comparison); these instructions set the carry flag if there is at least 1 bit set in the bit map. Note that the carry flag is set or cleared after the application of the polarity.
The zero flag indicates whether the src2 length is less than 16 (8 for word characters). For the (v)pcmpestri and (v)pcmpestrm instructions, the zero flag is set if EDX is less than 16 (8); for the (v)pcmpistri and (v)pcmpistrm instructions, the zero flag is set if XMMsrc2/memsrc2 contains a null character.
The sign flag indicates whether the src1 length is less than 16 (8 for word characters). For the (v)pcmpestri and (v)pcmpestrm instructions, the sign flag is set if EAX is less than 16 (8); for the (v)pcmpistri and (v)pcmpistrm instructions, the zero flag is set if XMMsrc1 contains a null character.
The overflow flag contains the setting for bit 0 of the result bit map (that is, whether the first character of the source string was a match). This can be useful after an equal ordered comparison to see if the substring is a prefix of the larger string (for example).
14.4 Alignment and Memory Management Unit Pages
The (v)pcmpXstrY instructions are nice insofar as they do not require their memory operand to be 16-byte aligned. However, this lack of alignment creates a special problem of its own: it is possible for a single (v)pcmpXstrY instruction memory access to cross an MMU page boundary. As noted in “Memory Access and 4K Memory Management Unit Pages” in Chapter 3, some MMU pages might not be accessible and will generate a general protection fault if the CPU attempts to read data from them.
If the string is less than 16 bytes in length and ends before the page boundary, using (v)pcmpXstrY to access that data may cause an inadvertent page fault when it reads a full 16 bytes from memory, including data beyond the end of the string. Though accessing data beyond the string that crosses into a new, inaccessible MMU page is a rare situation, it can happen, so you want to ensure you don’t access data across MMU page boundaries unless the next MMU page contains actual data.
If you have aligned an address on a 16-byte boundary and you access 16 bytes from memory starting at that address, you never have to worry about crossing into a new MMU page. MMU pages contain an integral multiple of 16 bytes (there are 256 16-byte blocks in an MMU page). If the CPU accesses 16 bytes starting at a 16-byte boundary, the last 15 bytes of that block will fall into the same MMU page as the first byte. This is why most SSE memory accesses are okay: they require 16-byte-aligned memory operands. The exceptions are the unaligned move instructions and the (v)pcmpXstrY instructions.
You typically use the unaligned move instructions (for example, movdqu and movupd) to move 16 actual bytes of data into an SSE/AVX register; therefore, these instructions don’t usually access extra bytes in memory. The (v)pcmpXstrY instructions, however, often access data bytes beyond the end of the actual string. These instructions read a full 16 bytes from memory even if the string consumes fewer than 16 of those bytes. Therefore, when using the (v)pcmpXstrY instructions (and the other unaligned moves, if you’re using them to read beyond the end of a data structure), you should ensure that the memory address you are supplying is at least 16 bytes before the end of an MMU page, or that the next page in memory contains valid data.
As Chapter 3 notes, there is no machine instruction that lets you test a page in memory to see if the application can legally access that page. So you have to ensure that no memory accesses by the (v)pcmpXstrY instructions will cross a page boundary. The next chapter provides several examples.
14.5 For More Information
Agner Fog is one of the world’s foremost experts on optimization of x86(-64) assembly language. His website (https://www.agner.org/optimize/#manuals/) has a lot to say about optimizing memory moves and other string instructions. This website is highly recommended if you want to write fast string code in x86 assembly language.
T. Herselman has spent a huge amount of time writing fast memcpy functions. You can find his results at https://www.codeproject.com/Articles/1110153/Apex-memmove-the-fastest-memcpy-memmove-on-x-x-EVE/ (or just search the web for Apex memmove). The length of this code will, undoubtedly, convince you to stick with the movs instruction (which runs fairly fast on modern x86-64 CPUs).
14.6 Test Yourself
- What size operands do the generic string instructions support?
- What are the five general-purpose string instructions?
- What size operands do the
pcmpXstrY instructions support? - What registers does the
repmovsbinstruction use? - What registers does the
cmpswinstruction use? - What registers does the
repnescasbinstruction use? - What registers does the
stosdinstruction use? - If you want to increment the RSI and RDI registers after each string operation, what direction flag setting do you use?
- If you want to decrement the RSI and RDI registers after each string operation, what direction flag setting do you use?
- If a function or procedure modifies the direction flag, what should that function do before returning?
- The Microsoft ABI requires a function to _ the direction flag before returning if it modifies the flag’s value.
- Which string instructions have Intel optimized for performance on later x86-64 CPUs?
- When would you want to set the direction flag prior to using a
movsinstruction? - When would you want to clear the direction flag prior to using a
movsinstruction? - What can happen if the direction flag is not set properly when you are executing a
movsinstruction? - Which string prefix would you normally use with
cmpsbto test two strings to see if they are equal? - When comparing two character strings, how should the direction flag normally be set?
- Do you need to test whether RCX is 0 before executing a string instruction with a repeat prefix?
- If you wanted to search for a zero-terminating byte in a C/C++ string, what (general-purpose) string instruction would be most appropriate?
- If you wanted to fill a block of memory with 0s, what string instruction would be most appropriate?
- If you wanted to concoct your own string operations, what string instruction(s) would you use?
- Which string instruction would you typically never use with a repeat prefix?
- Before using one of the
pcmpXstrY instructions, what should you do? - Which SSE string instructions automatically handle zero-terminated strings?
- Which SSE string instructions require an explicit length value?
- Where do you pass explicit lengths to the
pcmpXstrY instructions? - Which
pcmpXstrY aggregate operation searches for characters belonging to a set of characters? - Which
pcmpXstrY aggregate operation compares two strings? - Which
pcmpXstrY aggregate operation checks whether one string is a substring of another? - What is the problem with the
pcmpXstrY instruction and MMU pages?